久しぶりの投稿です。
最近何をやっていたかというと、はてなへの移行作業を行っていました。
移行先:http://d.hatena.ne.jp/dreamscrapround/
理由やら、どーやって移行したか、とかは下記の記事を参照。
http://d.hatena.ne.jp/dreamscrapround/20110629/1309381231
とりあえず、場所こそ移りましたが、投稿自体は同じような内容を続けるつもりではあります。
ブログをはてなに移行しました
Read User's Comments(0)
scalaで出来ることを並べてみる:Predef
scalaには一部メソッドだけでどのクラスからも呼び出せるメソッドがあります。
サンプルコード
■PredefMain.scala
package jp.gr.kmtn.scalatutorial.grammertips
/**
* Predef用メインクラス
*
* @author Fukushi-
*/
object PredefMain {
/**
* Predefテスト用プログラムエントリポイント
*/
def main(args: Array[String]): Unit =
{
// requireメソッド確認
// trueの場合何もしない
require(true);
// falseの場合java.lang.IllegalArgumentException発生
try {
require(false);
} catch { case ex: IllegalArgumentException => ex.printStackTrace() }
// printlnメソッドを実行すると自動的にConsole.printlnメソッドにマッピング
println("PredefMain");
}
}
実行結果
java.lang.IllegalArgumentException: requirement failed
at scala.Predef$.require(Predef.scala:145)
at jp.gr.kmtn.scalatutorial.grammertips.PredefMain$.main(PredefMain.scala:21)
at jp.gr.kmtn.scalatutorial.grammertips.PredefMain.main(PredefMain.scala)
PredefMain
解説
サンプル中で、require(boolean)というメソッドを呼び出していますが、このメソッドはscalaであればどんなソースからもメソッド呼び出しのみで使用できるメソッドです。
与えた引数によって例外を発生させることが出来ます。
コンストラクタでの初期化で不正な値を弾く際などに使えますね。
で、上記のメソッド群は「scala.Predef」というobjectで定義されています。
実はprintlnメソッドが自動的にConsole.printlnメソッドにマッピングされるのも
Predefobjectの動作によるものでした。
他にもJavaでいうプリミティブ型の変換処理、文字列変換、コンソールからの入出力などが揃っています。
さすがに前回のリッチラッパーとは違い、Predefを使用して好きな機能を追加。。。
とは行かないでしょうが、無駄なメソッドを作らずに済む点では使いやすいかと。
scalaで出来ることを並べてみる:演算子表現=メソッド表現&リッチラッパー
scalaはJavaと違って、演算子(+とか)が存在せず、全てメソッドで構成されているとなっています。
なんですが、イマイチそれだけ言われても実感できないので、
試してみました。
ついでにリッチラッパーの確認もやってました。
上のCase1-Xから見ていきましょう。
Case1-1ではInt型の変数を + で連結して加算を行っています。
Case1-2では、Int型変数のメソッド「+」を呼び出して加算を行っています。
Case1-1と、Case1-2の表現は等価です。
つまり、演算子のように見える「+」もメソッドでしかないことがわかりますね。
後、実際にInt型変数のメソッド一覧(Eclipseの補完一覧)を見てみると
演算子と同じメソッドが存在していることがわかります。

次は、Case2-Xの説明です。
Case1-Xとは逆に、splitメソッドを演算子形式で記述しています。
Case2-1、Case2-2の表現も等価です。
つまりはScalaでは下記の2つのことが言える、となりますね。
Javaと書き方自体は変えずに、背後で動く機構は統一されているようですね。なかなか新鮮。
後、最後にリッチラッパーについて。
下記のコードで、Int型に対してmaxというメソッドを使用しています。
なんですが、Int型にはmaxというメソッドは存在しません。
maxというメソッドが定義されているのは、「scala.runtime.RichInt」というクラスです。
下記のコードの中で、maxメソッド実行時に暗黙の型変換(Int→RichInt)がおこなわれてるため、
Int型の変数が直接maxメソッドを呼び出せるようです。
どういう仕組みなのかなぁ。。と思ってみてクラス構造を見てみた所、
「scala.runtime.ScalaNumberProxy」、「scala.runtime.ScalaNumberProxy」クラスが
リッチラッパーに絡んでいる模様。
更に背後には、「scala.Proxy」トレイトや、「scala.Proxy.Typed」トレイトが絡んでいる模様。
自分で今回のリッチラッパーのように既存のクラスに対して機能を追加できる、
追加機能の実行時にのみ暗黙的に型変換されるため
余計な考慮は不要というコードが作れたら面白そうですよね。
ただ、それについてはまたの機会に。
なんですが、イマイチそれだけ言われても実感できないので、
試してみました。
ついでにリッチラッパーの確認もやってました。
サンプルコード
■OperatorMethodMain.scala
package jp.gr.kmtn.scalatutorial.grammertips
/**
* 演算子/メソッド共通確認+リッチラッパー確認テスト用メインクラス
*
* @author Fukushi-
*/
object OperatorMethodMain {
/**
* 演算子/メソッド共通確認+リッチラッパー確認テスト用プログラムエントリポイント
*/
def main(args: Array[String]): Unit =
{
// 演算子動作確認
val two = 2
val five = 5
val nine = 9
// 演算子表現確認
Console.println("---Case 1-1 ---")
Console.println(two + five)
Console.println(nine - five)
// メソッド表現確認
Console.println("---Case 1-2 ---")
Console.println(two.+(five))
Console.println(nine.-(five))
// メソッド動作確認
val str = "Two,Five,Nine"
// 演算子表現確認
Console.println("---Case 2-1 ---")
val strArray = str split ","
strArray.foreach(Console.println(_))
// メソッド表現確認]
Console.println("---Case 2-2 ---")
str.split(",").foreach(Console.println(_))
// リッチラッパー用メソッド確認
Console.println("---RichWrapper ---")
Console.println(nine max five)
Console.println(nine.max(five))
}
}
実行結果
で、実行結果は下記のようになります。
---Case 1-1 ---
7
4
---Case 1-2 ---
7
4
---Case 2-1 ---
Two
Five
Nine
---Case 2-2 ---
Two
Five
Nine
---RichWrapper ---
9
9
コード解説
上のCase1-Xから見ていきましょう。
Case1-1ではInt型の変数を + で連結して加算を行っています。
Case1-2では、Int型変数のメソッド「+」を呼び出して加算を行っています。
Console.println(two + five) → Case1-1、「+」を演算子形式で記述
Console.println(two.+(five)) → Case1-2、「+」をメソッド形式で記述
Case1-1と、Case1-2の表現は等価です。
つまり、演算子のように見える「+」もメソッドでしかないことがわかりますね。
後、実際にInt型変数のメソッド一覧(Eclipseの補完一覧)を見てみると
演算子と同じメソッドが存在していることがわかります。
次は、Case2-Xの説明です。
Case1-Xとは逆に、splitメソッドを演算子形式で記述しています。
val strArray = str split "," → Case2-1、「split」を演算子形式で記述
val printArray = str.split(",") → Case2-2、「split」をメソッド形式で記述
Case2-1、Case2-2の表現も等価です。
つまりはScalaでは下記の2つのことが言える、となりますね。
1.演算子は存在せず、全てメソッドで構成されている
2.メソッドはJavaでいう演算子形式と、メソッド形式のどちらでも記述可能
Javaと書き方自体は変えずに、背後で動く機構は統一されているようですね。なかなか新鮮。
後、最後にリッチラッパーについて。
下記のコードで、Int型に対してmaxというメソッドを使用しています。
Console.println(nine max five)
Console.println(nine.max(five))
なんですが、Int型にはmaxというメソッドは存在しません。
maxというメソッドが定義されているのは、「scala.runtime.RichInt」というクラスです。
下記のコードの中で、maxメソッド実行時に暗黙の型変換(Int→RichInt)がおこなわれてるため、
Int型の変数が直接maxメソッドを呼び出せるようです。
どういう仕組みなのかなぁ。。と思ってみてクラス構造を見てみた所、
「scala.runtime.ScalaNumberProxy」、「scala.runtime.ScalaNumberProxy」クラスが
リッチラッパーに絡んでいる模様。
更に背後には、「scala.Proxy」トレイトや、「scala.Proxy.Typed」トレイトが絡んでいる模様。
自分で今回のリッチラッパーのように既存のクラスに対して機能を追加できる、
追加機能の実行時にのみ暗黙的に型変換されるため
余計な考慮は不要というコードが作れたら面白そうですよね。
ただ、それについてはまたの機会に。
scalaで出来ることを並べてみる:Applicationトレイト
現在、シングルトンオブジェクトの中にmainメソッドを作成して
その中に実際の処理を書いていますが、
Applicationトレイトを実装したコードを使うと、mainメソッドも省略できます。
■ApplicationTraitMain.scala
object ApplicationTraitMain extends Application {
val immutableMapFirst = Map(1 -> "One", 2 -> "Two")
val immutableMapSecond = immutableMapFirst + (3 -> "Three")
Console.println(immutableMapSecond.toString);
def getName(): String = { "name" }
}
処理内容的には前回の記事と同じです。
ですが、mainメソッドではなく、直接クラス定義に処理を記述しています。
Applicationトレイトを継承していると上記のような記述が可能です。
で、実際に実行した結果も下記のようになり、同じです。
■実行結果
Map(1 -> One, 2 -> Two, 3 -> Three)
尚、この記述の実行タイミングはmainメソッドとは違い、『クラスのロードタイミング』になっています。
#下記のキャプチャより

尚、前回のコードを用いて同じ確認を行うとmainメソッドを呼び出して実行しているため、
実行しているタイミングは明示的に違うようです。

実際にApplicationトレイトは何に使えるかというと、
小規模なプログラムを記述するときにmainメソッドを省略できるということと、
後は、『クラスロード時に呼ばれる』内容のため、クラスロード時の初期化を書くのがいいのかもしれません。
Javaでいうstaticブロックのようなノリでしょうか。
実際に、Applicationトレイト継承シングルトンオブジェクトに他のメソッドを定義することも可能でした。
#サンプルコードの「getNameメソッド」
ともあれ、それなりに規模が出てきた時にまた用途を試してみる必要がありそうです。
scalaで出来ることを並べてみる:Map
JavaやC#においてはMapオブジェクトというのは後で何かを追加して使いまわすために
用いられる『ミュータブルオブジェクト』という扱いが基本です。
ですが、scalaのような関数型言語では『イミュータブルオブジェクト』として扱うのが基本だそうな。
実際、Mapにも「scala.collection.mutable.Map」と、「scala.collection.immutable.Map」として
2種類クラスツリーが存在していています。
クラス名称的には微妙にわかりにくい気もしますが。
で、動作も下記のように違ってきています。
■ImmutableMapObjectMain.scala
package jp.gr.kmtn.scalatutorial.grammertips
import scala.collection.immutable.Map
/**
* イミュータブルMapテスト用メインクラス
*
* @author Fukushi-
*/
object ImmutableMapObjectMain {
/**
* イミュータブルMapテスト用プログラムエントリポイント
*/
def main(args: Array[String]): Unit =
{
val immutableMapFirst = Map(1 -> "One", 2 -> "Two")
val immutableMapSecond = immutableMapFirst + (3 -> "Three")
Console.println(immutableMapSecond.toString);
}
}
■MutableMapObjectMain.scala
package jp.gr.kmtn.scalatutorial.grammertips
import scala.collection.mutable.Map
/**
* ミュータブルMapテスト用メインクラス
*
* @author Fukushi-
*/
object MutableMapObjectMain {
/**
* ミュータブルMapテスト用プログラムエントリポイント
*/
def main(args: Array[String]): Unit =
{
val mutableMapFirst = Map[Int, String](1 -> "One", 2 -> "Two")
mutableMapFirst += (3 -> "Three")
Console.println(mutableMapFirst.toString);
}
}
実行結果はどちらも下記のようになります。
■実行結果
Map(3 -> Three, 1 -> One, 2 -> Two)
イミュータブルなMapの場合、+メソッドを使って新しいMapを生成する形で要素を追加。
ミュータブルなMapの場合、+=メソッドを使って新しい要素を追加する形になります。
イミュータブルMapの場合、既存のオブジェクトに影響を与えないことが保障されますが、
要素の追加を行う度に新規Mapが生成されるため、下手すると性能問題になるかもしれません。
ミュータブルMapの場合、既存のオブジェクトに追加されるため性能的には優れそうですが、
いつの間にか状態が変わっている可能性が出てきます。
この辺りを考慮して使い分けるのがよさそうです。
何にしても、使い分けられるのはいいですね。
scalaで出来ることを並べてみる:タプル
JavaやらC#でプログラムを書いていると、『返り値を複数返したい』ケースが出てきます。
特に、違う型の返り値を返したい場合が厄介です。
返り値を返すためだけにBeanクラスを作ったりする。。。というのは面倒ですからね。
・・・まぁ、返り値を複数返したい時点でクラス/メソッド設計が微妙という突っ込みはありますが、
それを言ってしまうと本末転倒なのでここでは省略します。
scalaでは返り値を複数返したい場合、Tupleという型があります。
一言でいえば、異なる型のインスタンスを格納可能なListという感じです。
イミュータブルで、異なる型のインスタンスを混在して格納出来て、型指定も可能。
とりあえず使ってみたサンプルは下記の通りです。
■TupleMain.scala
package jp.gr.kmtn.scalatutorial.grammertips
/**
* タプルテスト用メインクラス
*
* @author Fukushi-
*/
object TupleMain {
/**
* タプルテスト用プログラムエントリポイント
*/
def main(args: Array[String]): Unit =
{
val tuplePair = ("Arg1", 2)
Console.println(tuplePair);
Console.println(tuplePair.getClass());
Console.println(tuplePair._1);
Console.println(tuplePair._2);
val tuplePairGenerics: Tuple2[Int, String] = (100, "Arg2")
Console.println(tuplePairGenerics);
Console.println(tuplePairGenerics.getClass());
Console.println(tuplePairGenerics._1);
Console.println(tuplePairGenerics._2);
val tupleQuintet = ("Args1", 2, 3, "Args4", "Args5");
Console.println(tupleQuintet.getClass());
}
}
で、実行結果は下記の通り。
■実行結果
(Arg1,2)
class scala.Tuple2
Arg1
2
(100,Arg2)
class scala.Tuple2
100
Arg2
class scala.Tuple5
どうやら、指定した引数の数に応じてTuple2、Tuple3...という別々の型が用意されているようです。
いくつまであるかは興味深い所ですが、そんな増える時点で他の所を疑うべきなのは確かですね。
scalaで出来ることを並べてみる:シンボルリテラル
scalaでJavaに無い概念として、「シンボルリテラル」というものがあります。
言ってしまうと指定された文字列を持つラッパーみたいなもので、
同じ引数を指定されたシンボルリテラルはメモリ上で同じ参照を示すことが保障されます。
とまぁ、これだけかいてもわからないので、とりあえずサンプルコードと実行結果を。
■SimbolLiteralMain.scala
package jp.gr.kmtn.scalatutorial.grammertips
/**
* シンボルリテラルテスト用
*/
object SimbolLiteralMain {
/**
* シンボルリテラルテスト用プログラムエントリポイント
*/
def main(args: Array[String]): Unit =
{
val simbolFirst = 'Simbol
Console.println(simbolFirst);
Console.println(simbolFirst.getClass())
val simbolSecond = 'Simbol
Console.println(simbolSecond)
Console.println(simbolSecond.toString())
Console.println(simbolSecond.getClass())
Console.println(simbolSecond.name)
}
}
このコードを実行すると下記の結果になります。
'Simbol
class scala.Symbol
'Simbol
'Simbol
class scala.Symbol
Simbol
実際に同じシンボルリテラルは同じオブジェクトを使用していることが分かります。
(simbolFirstとsimbolSecondは同じオブジェクトID)

注意すべきは、「シンボルリテラル」≠「文字列リテラル」ということです。
シンボルリテラルは文字列とは比較できません。
そもそも型が違うため、マップで比較することも出来ません。
そのため、シンボルリテラル中の文字列リテラルを使用する際にはnameフィールドを参照しましょう。
nameフィールドで文字列と簡単に比較できるため、
プログラム内部での定数取り回しの記述はかなり少なく出来る。。。のかな?
駄目ネタで試すScala 名前付き引数 ~魔法少女まどか☆マギカ編~
前回残っていた、『途中の引数を省略する場合はどうすればいいのか?』について。
デフォルト値によって引数が省略できるにしても、
『どの引数を指定し、どの引数を省略するか?』が指定できないと実際にはまともに使えません。
そんなわけで、scalaでは引数に名前を下記のように指定することが可能です。
メソッド名(引数名1 = 引数1, 引数名2 = 引数2, 引数名3 = 引数3)
実際に使ってみた例が下記。
■NamedArgsMain.scala
package jp.gr.kmtn.scalatutorial.defaultvalue
/**
* 名前付き引数確認用メインクラス
*
* @author Fukushi-
*/
object NamedArgsMain {
/**
* 名前付き引数確認用プログラムエントリポイント
*/
def main(args: Array[String]): Unit =
{
val ancientPuellaA = new PuellaMagi
ancientPuellaA.sealToSoulJem("古代の魔法少女A")
val ancientPuellaAA = new PuellaMagi
ancientPuellaAA.sealToSoulJem(name = "古代の魔法少女AA")
val ancientPuellaB = new PuellaMagi
ancientPuellaB.sealToSoulJem("古代の魔法少女B", "魔法の剣")
val ancientPuellaBB = new PuellaMagi
ancientPuellaBB.sealToSoulJem(name = "古代の魔法少女BB", weapon = "魔法の剣")
val ancientPuellaC = new PuellaMagi
ancientPuellaC.sealToSoulJem(name = "古代の魔法少女C", magica = "この世の呪い")
val madoca = new PuellaMagi
madoca.sealToSoulJem("鹿目 まどか", "薔薇の枝の弓矢", "魔女を全ての時空から生まれる前に消しさる宇宙法則")
val homura = new PuellaMagi
homura.sealToSoulJem(name = "暁美 ほむら", weapon = "時の砂時計の盾", magica = "時間操作")
val sayaka = new PuellaMagi
sayaka.sealToSoulJem(magica = "治癒の魔法", weapon = "サーベル", name = "美樹 さやか")
Console.println(ancientPuellaA)
Console.println(ancientPuellaAA)
Console.println(ancientPuellaB)
Console.println(ancientPuellaBB)
Console.println(ancientPuellaC)
Console.println(madoca)
Console.println(homura)
Console.println(sayaka)
}
}
実際に実行した結果は下記の通り。
魔法少女 名前:古代の魔法少女A 武器:魔法のステッキ 固有魔法:光の魔法
魔法少女 名前:古代の魔法少女AA 武器:魔法のステッキ 固有魔法:光の魔法
魔法少女 名前:古代の魔法少女B 武器:魔法の剣 固有魔法:光の魔法
魔法少女 名前:古代の魔法少女BB 武器:魔法の剣 固有魔法:光の魔法
魔法少女 名前:古代の魔法少女C 武器:魔法のステッキ 固有魔法:この世の呪い
魔法少女 名前:鹿目 まどか 武器:薔薇の枝の弓矢 固有魔法:魔女を全ての時空から生まれる前に消しさる宇宙法則
魔法少女 名前:暁美 ほむら 武器:時の砂時計の盾 固有魔法:時間操作
魔法少女 名前:美樹 さやか 武器:サーベル 固有魔法:治癒の魔法
下記のように引数の名前を指定することで、順不同で引数指定することが可能です。
homura.sealToSoulJem(name = "暁美 ほむら", weapon = "時の砂時計の盾", magica = "時間操作")
sayaka.sealToSoulJem(magica = "治癒の魔法", weapon = "サーベル", name = "美樹 さやか")
とまぁ、ただ当然ながら下記のような制約もあります。
1.名前付き引数と名前なし引数を1回のメソッド呼び出しの中に混在させることは出来ない
2.デフォルト値が定義されていない引数を省略してメソッド呼び出しをすることは出来ない
名前付き引数は多少記述が冗長になるかもしれませんが、
メソッド呼び出し部を見るだけで引数の大体の用途が分かるというのは非常に便利ですね。
駄目ネタで試すScala 引数 ~魔法少女まどか☆マギカ編~
てなわけで(?) ネタ編第2回です。
適切なネタがパッと他に思い浮かばなかったので今回も魔法少女まどか☆マギカ継続で。
今度は何をネタにするかなぁ。。。。
オブジェクト指向言語に限らず、
クラスやメソッドで、
『いくつかの引数は省略しても動くようにしたい』ということはよくあると思います。
その時、Javaだと下記のように同名メソッドをオーバーロードして
同名メソッドをいくつも記述することになります。
■PuellaMagi.scala(変更前)
package jp.gr.kmtn.scalatutorial.defaultvalue
/**
* 「魔法少女」クラス
*
* @author Fukushi-
*/
class PuellaMagi() {
/**
* 名前を示すフィールド
*/
var name_ = "";
/**
* 保持する武器を示すフィールド
*/
var weapon_ = "";
/**
* 固有魔法を示すフィールド
*/
var magica_ = "";
/**
* 契約を行い、魂をソウルジェムに移して肉体をハードウェアに変換する。
*
* @param name 名前
*/
def sealToSoulJem(name: String) =
{
this.name_ = name;
this.weapon_ = "魔法のステッキ";
this.magica_ = "光の魔法";
}
/**
* 契約を行い、魂をソウルジェムに移して肉体をハードウェアに変換する。
*
* @param name 名前
* @param weapon 保持する武器
*/
def sealToSoulJem(name: String, weapon: String) =
{
this.name_ = name;
this.weapon_ = weapon;
this.magica_ = "光の魔法";
}
/**
* 契約を行い、魂をソウルジェムに移して肉体をハードウェアに変換する。
*
* @param name 名前
* @param weapon 保持する武器
* @param magica 固有魔法
*/
def sealToSoulJem(name: String, weapon: String, magica: String) =
{
this.name_ = name;
this.weapon_ = weapon;
this.magica_ = magica;
}
override def toString()=
{
"魔法少女 名前" + this.name_ + " 武器:" + this.weapon_ + " 固有魔法:" + this.magica_
}
でもこれだと正直な話冗長ですよね。
同じメソッドをいくつも書くことになってしまう。
scalaの場合下記のように『引数のデフォルト値』を指定することが可能です。
■PuellaMagi.scala(変更後)
package jp.gr.kmtn.scalatutorial.defaultvalue
/**
* 「魔法少女」クラス
*
* @author Fukushi-
*/
class PuellaMagi() {
/**
* 名前を示すフィールド
*/
var name_ = "";
/**
* 保持する武器を示すフィールド
*/
var weapon_ = "";
/**
* 固有魔法を示すフィールド
*/
var magica_ = "";
/**
* 契約を行い、魂をソウルジェムに移して肉体をハードウェアに変換する。
*
* @param name 名前
* @param weapon 保持する武器 デフォルト値=魔法のステッキ
* @param weapon 固有魔法 デフォルト値=光の魔法
*/
def sealToSoulJem(name: String, weapon: String = "魔法のステッキ", magica: String = "光の魔法") =
{
this.name_ = name;
this.weapon_ = weapon;
this.magica_ = magica;
}
override def toString()=
{
"魔法少女 名前:" + this.name_ + " 武器:" + this.weapon_ + " 固有魔法:" + this.magica_
}
}
こうすると、デフォルトの値が定義されている引数については、
メソッド呼び出し時に値が渡されなくても自動的にデフォルトで指定した値が用いられるわけです。
実際に使ってみた例を書いてみましょう。
■DefaultValueMain.scala
package jp.gr.kmtn.scalatutorial.defaultvalue
/**
* 引数デフォルト値確認用メインクラス
*
* @author Fukushi-
*/
object DefaultValueMain {
/**
* 引数デフォルト値確認用プログラムエントリポイント
*/
def main(args: Array[String]): Unit =
{
val ancientPuellaA = new PuellaMagi
ancientPuellaA.sealToSoulJem("古代の魔法少女A")
val ancientPuellaB = new PuellaMagi
ancientPuellaB.sealToSoulJem("古代の魔法少女B", "魔法の剣")
val madoca = new PuellaMagi
madoca.sealToSoulJem("鹿目 まどか", "薔薇の枝の弓矢", "魔女を全ての時空から生まれる前に消しさる宇宙法則")
Console.println(ancientPuellaA)
Console.println(ancientPuellaB)
Console.println(madoca)
}
}
■実行結果
魔法少女 名前:古代の魔法少女A 武器:魔法のステッキ 固有魔法:光の魔法
魔法少女 名前:古代の魔法少女B 武器:魔法の剣 固有魔法:光の魔法
魔法少女 名前:鹿目 まどか 武器:薔薇の枝の弓矢 固有魔法:魔女を全ての時空から生まれる前に消しさる宇宙法則
こんな感じで、引数を指定しなかった場合、
デフォルトで定義された値が用いられたのがわかると思います。
ただ、これだけだとまだ問題があります。
『途中の引数を省略する場合はどうすればいいのか?』という問題ですね。
とりあえず、それは次回にでも。
駄目ネタで試すScala Actor ~魔法少女まどか☆マギカ編~解説
というわけで、前回投稿中のコードを解説。
■Homo.scala
abstract class Homo(name: String) {
/**
* 名前を文字列型で返す抽象メソッド
*/
def getName(): String
}
オブジェクト指向言語ではおなじみの抽象クラスです。
コンストラクタとして、String型の引数を渡す構成になっています。
尚、コンストラクタの引数にvalを付けると継承メソッド側でエラーとなります。
valはfinalと同様の扱いのため、後から変更することが出来ないためです。
その上で、名前を取得するgetNameメソッドを持ちます。
メソッド本体を定義しなければ自動的に抽象メソッド化されるため、
メソッド側には特にabstractは記述していません。
■Puella.scala
class Puella(name: String) extends Homo(name) {
/**
* 初期化時の名前を取得し、返す。
*/
def getName(): String = { this.name; }
}
人間クラスを継承した少女クラスです。
親クラスのコンストラクタをそのまま使用しています。
尚、getNameメソッドの中ではインスタンスフィールドnameを使用していますが、
これはscalaがコンストラクタの引数に指定した変数名と同名のprivateフィールドを
自動生成して保持するため使用可能になっています。
■Incubator.scala
object Incubator extends Actor {
/**
* メッセージ待ち受けメソッド
*/
def act() {
loop {
receive {
case puellaMagi: PuellaMagi =>
Console.println(puellaMagi.getName() + "、やがて「魔女」になる君たちのことは「魔法少女」と呼ぼう。");
case puella: Puella =>
Console.println(puella.getName() + "、僕と契約して魔法少女になってよ。");
case homo: Homo =>
Console.println(homo.getName() + "、残念ながら君には用は無いなぁ。");
case "exit" =>
Console.println("それじゃあね。"); exit;
exit;
case any: Any =>
Console.println("訳が分からないよ。");
}
}
}
}
objectのインキュベータークラスです。
loopの中のcase分岐を見ればわかるように、
与えられたメッセージクラスに応じて挙動を変えられるようになっています。
マッチングはcase分岐の上から行われ、マッチした処理が実行されます。
Mainメソッド側を見ればわかりますが、
caseにHomoを指定していた場合、子クラス全てがマッチします。
■IncubatorMain.scala
def main(args: Array[String]): Unit = {
// Actor起動
Incubator.start();
Incubator ! new Puella("鹿目 まどか")
Incubator ! new PuellaMagi("美樹 さやか")
Incubator ! new Puer("上条 恭介")
Incubator ! "UnKnown"
Incubator ! "exit"
}
}
Incubatorクラスをstartで起動し、
そこにオブジェクトのメッセージを渡すことで挙動を確認しています。
渡したクラスに応じてActorの挙動が変わっていることが分かりますね。
処理をディスパッチしたり、唯一のデータアクセスオブジェクトを定義したりと、
なかなか面白い使い方が出来そうです。Actor。
駄目ネタで試すScala Actor ~魔法少女まどか☆マギカ編~
前回でIDEの使い方がわかったので、コーディングの効率がかなり増しました。
これで足場は揃ったので、今回からはscalaの要素等を色々試していこうと思います。
で、今回はActorです。
使ったコードは下記の通り。ネタはお察しください(笑
ネタの関係上、Actorに渡すクラス群の名称は全てラテン語になってます。
■Homo.scala
package jp.gr.kmtn.scalatutorial.incubator
/**
* 「人間」クラス
*
* @author Fukushi-
*/
abstract class Homo(name: String) {
/**
* 名前を文字列型で返す抽象メソッド
*/
def getName(): String
}
■Puella.scala
package jp.gr.kmtn.scalatutorial.incubator
/**
* 「少女」クラス
*
* @author Fukushi-
*/
class Puella(name: String) extends Homo(name) {
/**
* 初期化時の名前を取得し、返す。
*/
def getName(): String = { this.name; }
}
■PuellaMagi.scala
package jp.gr.kmtn.scalatutorial.incubator
/**
* 「魔法少女」クラス
* 動作は「少女」クラスに準ずる
*
* @author Fukushi-
*/
class PuellaMagi(name: String) extends Puella(name) {
}
■Puer.scala
package jp.gr.kmtn.scalatutorial.incubator
/**
* 「少年」クラス
*
* @author Fukushi-
*/
class Puer(name: String) extends Homo(name) {
/**
* 初期化時の名前を取得し、返す。
*/
def getName(): String = { this.name; }
}
■Incubator.scala
package jp.gr.kmtn.scalatutorial.incubator
import scala.actors.Actor
/**
* Actor確認用クラス。キュゥべぇ。
*
* @author Fukushi-
*/
object Incubator extends Actor {
/**
* メッセージ待ち受けメソッド
*/
def act() {
loop {
receive {
case puellaMagi: PuellaMagi =>
Console.println(puellaMagi.getName() + "、やがて「魔女」になる君たちのことは「魔法少女」と呼ぼう。");
case puella: Puella =>
Console.println(puella.getName() + "、僕と契約して魔法少女になってよ。");
case homo: Homo =>
Console.println(homo.getName() + "、残念ながら君には用は無いなぁ。");
case "exit" =>
Console.println("それじゃあね。"); exit;
exit;
case any: Any =>
Console.println("訳が分からないよ。");
}
}
}
}
上記がパーツで、実際に実行するプログラムエントリポイントは下記の通り。
■IncubatorMain.scala
package jp.gr.kmtn.scalatutorial.incubator
/**
* Actor確認用Mainクラス
*
* @author Fukushi-
*/
object IncubatorMain {
/**
* Actor確認用プログラムエントリポイント
*/
def main(args: Array[String]): Unit = {
// Actor起動
Incubator.start();
Incubator ! new Puella("鹿目 まどか")
Incubator ! new PuellaMagi("美樹 さやか")
Incubator ! new Puer("上条 恭介")
Incubator ! "UnKnown"
Incubator ! "exit"
}
}
実行すると、下記の結果となります。
鹿目 まどか、僕と契約して魔法少女になってよ。
美樹 さやか、やがて「魔女」になる君たちのことは「魔法少女」と呼ぼう。
上条 恭介、残念ながら君には用は無いなぁ。
訳が分からないよ。
それじゃあね。
とりあえず、解説は次投稿で。
Scala Plugin for EclipseでJavaと同じように出来ること一覧(その1)
とりあえず、導入してみた後、Javaと同じような便利機能がどれだけ出来るかを試してみました。
下記のような開発時に頻度が高くものは一通り出来そう。
出てそれなりに時間がたっているせいか、機能は備わっているようです。
特に、変数名のリネームや呼び出し階層、リファクタ系メニューが普通に使えるのは大きい。
出来ない機能は。。。ま、明らかになり次第ブログに書きます。
■出来る
-コードフォーマット(Shift + Ctrl + F) → フォーマッタはまだ微妙
-変数名/クラス名のリネーム(Shift + Alt + R)
-型階層の表示(F4) → 出来るが、ルートクラスはAnyではなくObjectが表示される。微妙
-呼び出し階層の表示(Ctrl + Alt + H)
-コメントの雛型自動生成(Shift + Alt + J) → /** で書き出すより、こちらの方が優秀
-リファクタ系メニューがそれなりに
-SDKの中のクラスが一部見える(Ctrl + マウスクリック)
-デバッグ実行&ブレークポイントでの停止
Scala Plugin For Eclipse
とりあえずある程度書けるようになったらIDEが欲しくなってしまうのがプログラマのサガですよね。
Javaで現状一番経験があるIDEはEclipseなので、
Eclipseベースのscala開発環境もあるだろう。。。。と見てみたところ、普通にありました。
Scala IDE for Eclipse
Eclipse3.6.2 HeliosのUpdateサイトにscalaのものを設定したら普通にダウンロード&導入完了。
{kind=link}

次はscalaプロジェクトの作成ですね。
新しいプロジェクトを作成しようとすると、ScalaProjectが追加されています。


プロジェクトを作成したので、次はソースを作成します。
ClassとObjectがわけて作れる辺りが微妙に便利。


Javaでは当たり前の話ですが、きちんとscalaでも自動補完してくれました。
うーん、やはりこれを知ってしまうとテキストうちのプログラミングには戻れないですねぇ。

とりあえず再度Hello Worldプログラムを記述。
途中でちと気になったのは、「scaladocってどんな感じ?」ということ。
習性のようにコメント入れようとしたら、argsとかのコメントは補完されませんでしたので。
とまぁ、それはそれで。

で、ここまでコードを書いたら後は「Run As」メニューから「Scala Application」を実行するだけですね。

で、実行すると無事コンソールに実行結果が表示されました。
これで基本のきは一本通りましたね~。
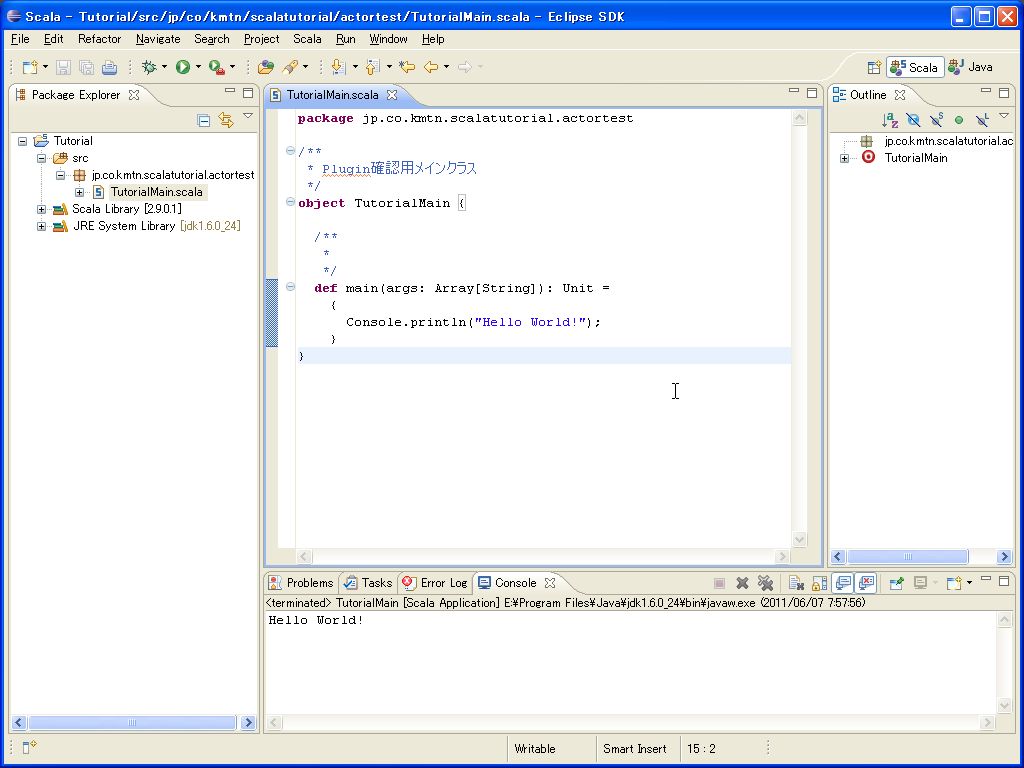
HelloWorld改造版(別クラス参照)でのscalaの特徴とメリットデメリット
とりあえず基本型のコードは書いたのでその中で出てくるscalaの特徴と、
メリットデメリットについてまとめます。
ただ、私がベースがJava/C#プログラマな関係上、
どーしてもその2つの言語との比較になってしまうのでご注意。
1.変数に型宣言が不要
下記のコードを見てわかるように、変数に型宣言必要ありません。
ただ、valという変数を示す宣言があるだけです。
val upper = hellos.map((s:String) => s.toUpperCase())
メリットとしては、型宣言が必要ないため、
1つの関数をより汎用的に様々なクラスで使用できること。
デメリットとしては型宣言が無い関係上その瞬間での型制約が出来ず、
変数からメソッドを呼び出す場合に問題になる可能性が大きい、あたりでしょうか。
メリット:
1つの関数をより汎用的に使用可能。
デメリット:
変数の型に制約が無いため、実行時にエラーとなる可能性があがる。
2.逐次実行時一時的な変数に代入する必要が無い
下記の2行目のように、逐次実行時に一時的な変数に代入する必要がありません。
→ 1行目のように代入(変数:s)して明確にした上で実行することも可能。
_という無名の変数を用いて表現できてしまう。
val upper = hellos.map((s:String) => s.toUpperCase())
upper.foreach(Console.println(_))
これはかなり大きいメリットがあるかと。
なにせ、一時変数がわらわら出来てしまうことがなくなり、可読性がよくなりますので。
但し、デバッグの時に微妙に大変そうだなぁ、とは思います。
リモートデバッグで無名変数ってどーやって指定するんだろ。。。。
メリット:
一時変数を削減し、コードの可読性が向上
デメリット:
デバッグが困難(?)
こんな感じかな。
とりあえず今後もコード書く→特徴まとめるのサイクルをまわしていくか。
HelloWorld改造版(別クラス参照)
今まで生半可理解だったから色々身にしみる。。。というのはさておき。
HelloWorldを改造して、下記のソースを作成しました。
■HelloWhile.scala
class HelloWhile {
def hello(hellos: String*) = {
val upper = hellos.map((s:String) => s.toUpperCase())
Console.println(upper)
upper.foreach(Console.println(_))
}
}
■HelloWorld.scala
object HelloWorld {
def main(args: Array[String]) {
val helloWhile = new HelloWhile
helloWhile.hello("hello", "hellohello", "hellohellohello")
}
}
そんでもって、下記のようにコンパイルして実行します。
C:\work>scalac HelloWhile.scala
C:\work>scalac -cp . HelloWorld.scala
C:\work>scala -cp . HelloWorld
ArrayBuffer(HELLO, HELLOHELLO, HELLOHELLOHELLO)
HELLO
HELLOHELLO
HELLOHELLOHELLO
C:\work>
これでHelloWorldですが、別クラスを参照するHelloWorldの完成。
Javaを知っていると大体分かるんですが、微妙に違う個所も多くあります。
まず、目につくのがクラス宣言の「class HelloWhile」と「object HelloWorld」。
classが通常のクラス定義で、objectがシングルトン定義を表します。
なので、scalaのプログラムを起動する場合はシングルトン定義の中に
mainメソッドを定義して呼び出せばそこから処理がスタートするわけですね。
後は。。。「def hello(hellos: String*) = {...」の個所でしょうか。
さすが関数型言語なだけあって、メソッド自体もイコールでつないで定義しています。
加えて、「Console.println(upper)」→「ArrayBuffer(HELLO, HELLOHELLO, HELLOHELLOHELLO)」
となるように、単にプリントを行った際に型が出力されるのがJavaとは違う所。
他にも何か色々ありますが、ここまで。とりあえずはひたすら書いてみます。。。
HelloWorldプログラムの実行
インストールが終わったので、定番のHelloWorldプログラムを実行してみます。
・・・なんですが、実行手段は下記の通り3通りあったりします。
- 対話方式による実行
- スクリプトによる実行
- コンパイルしての実行
各実行方式の違いについてはまた別記事で。
1.対話方式による実行
scalaコマンドでインタプリタを起動します。
んでもって、下記の通りにコマンドラインに入力し、確認を行います。
背後でどうJavaのオブジェクトにマッピングされているかが出力されるのが面白い所ですね。
C:\>scala
Welcome to Scala version 2.9.0.1 (Java HotSpot(TM) Client VM, Java 1.6.0_14).
Type in expressions to have them evaluated.
Type :help for more information.
scala> val message = "Hello World!"
message: java.lang.String = Hello World!
scala> println(message);
Hello World!
scala>
2.スクリプトによる実行
scalaコマンドにコードが書かれた内容を渡して、実行させます。
一番簡易に実行できる方式ですね。
■HelloWorld-script.scala
val message = "Hello World!"
println(message);
■実行
C:\work>scala HelloWorld-script.scala
Hello World!
3.コンパイルしての実行
予め書いたコードをコンパイルしてclassファイルを生成して、
それを実行させます。
対話方式やスクリプトによる実行とは異なり、クラスとしての構文が必要となります。
■HelloWorld.scala
object HelloWorld {
def main(args: Array[String]) {
println("Hello World!")
}
}
■実行
C:\work>scalac HelloWorld.scala
C:\work>dir
C:\work のディレクトリ
2011/06/02 09:42 <DIR> .
2011/06/02 09:42 <DIR> ..
2011/06/02 09:42 605 HelloWorld$.class
2011/06/02 09:34 47 HelloWorld-script.scala
2011/06/02 09:42 637 HelloWorld.class
2011/06/02 09:41 91 HelloWorld.scala
4 個のファイル 1,380 バイト
2 個のディレクトリ 25,740,607,488 バイトの空き領域
C:\work>scala HelloWorld
Hello World!
C:\work>
Scalaのインストール
復習として、インストールからも一度書いてみます。
Scalaの動作前提は下記です。
- Java1.5以上がインストールされていること
てなわけで、一応Javaがインストールされていることを確認。
OK。
なので、Scalaのインストールに入ります。
ScalaのHPから、Windows用のアーカイブをダウンロードします。
適当な場所に展開して、scala~\binのディレクトリにパスを通します。
んでもってScalaのパス開通確認。

こちらもOK。
画像ばかりで記事が長くなりそうなので一端切ります。
Scalaを導入(?)しました
てなわけで(?)、題名の通り、Scalaを導入しました。
今まで技術要素としてAndroidについて色々投稿していたんですが、
単なるJavaとの違いを出すためにはどうしても
Android固有の技術要素について書かざるをえなかったんですよね。
AndroidでデザインパターンをやってもJavaでしかないわけですし。
ただ、それって検索すれば大抵見つかるもの。
んでもって、どちらかと言うと技術要素の個々を書くよりは
汎用的なプログラミングについて書いてみたかったのもありますので。
というわけで(?)、Scalaの導入から、書き方、環境についても色々書いてみることにしました。
Androidアプリを弄るのは続いているので、時々出てくるかもしれませんが、それはそれで。
デザイン変更
とりあえず、デザインを変更。
Bloggerのテンプレートサイトを漁って集積場というか、埋め立て地っぽいのを持ってきました。
色々カスタマイズ出来ることもよーやっとわかりました。
余計な上部の表示も削除して、表示領域も拡張。
うし、では続いて何か書くか。
登録:
投稿 (Atom)