久しぶりの投稿です。
最近何をやっていたかというと、はてなへの移行作業を行っていました。
移行先:http://d.hatena.ne.jp/dreamscrapround/
理由やら、どーやって移行したか、とかは下記の記事を参照。
http://d.hatena.ne.jp/dreamscrapround/20110629/1309381231
とりあえず、場所こそ移りましたが、投稿自体は同じような内容を続けるつもりではあります。
ブログをはてなに移行しました
Read User's Comments(0)
scalaで出来ることを並べてみる:Predef
scalaには一部メソッドだけでどのクラスからも呼び出せるメソッドがあります。
サンプルコード
■PredefMain.scala
package jp.gr.kmtn.scalatutorial.grammertips
/**
* Predef用メインクラス
*
* @author Fukushi-
*/
object PredefMain {
/**
* Predefテスト用プログラムエントリポイント
*/
def main(args: Array[String]): Unit =
{
// requireメソッド確認
// trueの場合何もしない
require(true);
// falseの場合java.lang.IllegalArgumentException発生
try {
require(false);
} catch { case ex: IllegalArgumentException => ex.printStackTrace() }
// printlnメソッドを実行すると自動的にConsole.printlnメソッドにマッピング
println("PredefMain");
}
}
実行結果
java.lang.IllegalArgumentException: requirement failed
at scala.Predef$.require(Predef.scala:145)
at jp.gr.kmtn.scalatutorial.grammertips.PredefMain$.main(PredefMain.scala:21)
at jp.gr.kmtn.scalatutorial.grammertips.PredefMain.main(PredefMain.scala)
PredefMain
解説
サンプル中で、require(boolean)というメソッドを呼び出していますが、このメソッドはscalaであればどんなソースからもメソッド呼び出しのみで使用できるメソッドです。
与えた引数によって例外を発生させることが出来ます。
コンストラクタでの初期化で不正な値を弾く際などに使えますね。
で、上記のメソッド群は「scala.Predef」というobjectで定義されています。
実はprintlnメソッドが自動的にConsole.printlnメソッドにマッピングされるのも
Predefobjectの動作によるものでした。
他にもJavaでいうプリミティブ型の変換処理、文字列変換、コンソールからの入出力などが揃っています。
さすがに前回のリッチラッパーとは違い、Predefを使用して好きな機能を追加。。。
とは行かないでしょうが、無駄なメソッドを作らずに済む点では使いやすいかと。
scalaで出来ることを並べてみる:演算子表現=メソッド表現&リッチラッパー
scalaはJavaと違って、演算子(+とか)が存在せず、全てメソッドで構成されているとなっています。
なんですが、イマイチそれだけ言われても実感できないので、
試してみました。
ついでにリッチラッパーの確認もやってました。
上のCase1-Xから見ていきましょう。
Case1-1ではInt型の変数を + で連結して加算を行っています。
Case1-2では、Int型変数のメソッド「+」を呼び出して加算を行っています。
Case1-1と、Case1-2の表現は等価です。
つまり、演算子のように見える「+」もメソッドでしかないことがわかりますね。
後、実際にInt型変数のメソッド一覧(Eclipseの補完一覧)を見てみると
演算子と同じメソッドが存在していることがわかります。

次は、Case2-Xの説明です。
Case1-Xとは逆に、splitメソッドを演算子形式で記述しています。
Case2-1、Case2-2の表現も等価です。
つまりはScalaでは下記の2つのことが言える、となりますね。
Javaと書き方自体は変えずに、背後で動く機構は統一されているようですね。なかなか新鮮。
後、最後にリッチラッパーについて。
下記のコードで、Int型に対してmaxというメソッドを使用しています。
なんですが、Int型にはmaxというメソッドは存在しません。
maxというメソッドが定義されているのは、「scala.runtime.RichInt」というクラスです。
下記のコードの中で、maxメソッド実行時に暗黙の型変換(Int→RichInt)がおこなわれてるため、
Int型の変数が直接maxメソッドを呼び出せるようです。
どういう仕組みなのかなぁ。。と思ってみてクラス構造を見てみた所、
「scala.runtime.ScalaNumberProxy」、「scala.runtime.ScalaNumberProxy」クラスが
リッチラッパーに絡んでいる模様。
更に背後には、「scala.Proxy」トレイトや、「scala.Proxy.Typed」トレイトが絡んでいる模様。
自分で今回のリッチラッパーのように既存のクラスに対して機能を追加できる、
追加機能の実行時にのみ暗黙的に型変換されるため
余計な考慮は不要というコードが作れたら面白そうですよね。
ただ、それについてはまたの機会に。
なんですが、イマイチそれだけ言われても実感できないので、
試してみました。
ついでにリッチラッパーの確認もやってました。
サンプルコード
■OperatorMethodMain.scala
package jp.gr.kmtn.scalatutorial.grammertips
/**
* 演算子/メソッド共通確認+リッチラッパー確認テスト用メインクラス
*
* @author Fukushi-
*/
object OperatorMethodMain {
/**
* 演算子/メソッド共通確認+リッチラッパー確認テスト用プログラムエントリポイント
*/
def main(args: Array[String]): Unit =
{
// 演算子動作確認
val two = 2
val five = 5
val nine = 9
// 演算子表現確認
Console.println("---Case 1-1 ---")
Console.println(two + five)
Console.println(nine - five)
// メソッド表現確認
Console.println("---Case 1-2 ---")
Console.println(two.+(five))
Console.println(nine.-(five))
// メソッド動作確認
val str = "Two,Five,Nine"
// 演算子表現確認
Console.println("---Case 2-1 ---")
val strArray = str split ","
strArray.foreach(Console.println(_))
// メソッド表現確認]
Console.println("---Case 2-2 ---")
str.split(",").foreach(Console.println(_))
// リッチラッパー用メソッド確認
Console.println("---RichWrapper ---")
Console.println(nine max five)
Console.println(nine.max(five))
}
}
実行結果
で、実行結果は下記のようになります。
---Case 1-1 ---
7
4
---Case 1-2 ---
7
4
---Case 2-1 ---
Two
Five
Nine
---Case 2-2 ---
Two
Five
Nine
---RichWrapper ---
9
9
コード解説
上のCase1-Xから見ていきましょう。
Case1-1ではInt型の変数を + で連結して加算を行っています。
Case1-2では、Int型変数のメソッド「+」を呼び出して加算を行っています。
Console.println(two + five) → Case1-1、「+」を演算子形式で記述
Console.println(two.+(five)) → Case1-2、「+」をメソッド形式で記述
Case1-1と、Case1-2の表現は等価です。
つまり、演算子のように見える「+」もメソッドでしかないことがわかりますね。
後、実際にInt型変数のメソッド一覧(Eclipseの補完一覧)を見てみると
演算子と同じメソッドが存在していることがわかります。
次は、Case2-Xの説明です。
Case1-Xとは逆に、splitメソッドを演算子形式で記述しています。
val strArray = str split "," → Case2-1、「split」を演算子形式で記述
val printArray = str.split(",") → Case2-2、「split」をメソッド形式で記述
Case2-1、Case2-2の表現も等価です。
つまりはScalaでは下記の2つのことが言える、となりますね。
1.演算子は存在せず、全てメソッドで構成されている
2.メソッドはJavaでいう演算子形式と、メソッド形式のどちらでも記述可能
Javaと書き方自体は変えずに、背後で動く機構は統一されているようですね。なかなか新鮮。
後、最後にリッチラッパーについて。
下記のコードで、Int型に対してmaxというメソッドを使用しています。
Console.println(nine max five)
Console.println(nine.max(five))
なんですが、Int型にはmaxというメソッドは存在しません。
maxというメソッドが定義されているのは、「scala.runtime.RichInt」というクラスです。
下記のコードの中で、maxメソッド実行時に暗黙の型変換(Int→RichInt)がおこなわれてるため、
Int型の変数が直接maxメソッドを呼び出せるようです。
どういう仕組みなのかなぁ。。と思ってみてクラス構造を見てみた所、
「scala.runtime.ScalaNumberProxy」、「scala.runtime.ScalaNumberProxy」クラスが
リッチラッパーに絡んでいる模様。
更に背後には、「scala.Proxy」トレイトや、「scala.Proxy.Typed」トレイトが絡んでいる模様。
自分で今回のリッチラッパーのように既存のクラスに対して機能を追加できる、
追加機能の実行時にのみ暗黙的に型変換されるため
余計な考慮は不要というコードが作れたら面白そうですよね。
ただ、それについてはまたの機会に。
scalaで出来ることを並べてみる:Applicationトレイト
現在、シングルトンオブジェクトの中にmainメソッドを作成して
その中に実際の処理を書いていますが、
Applicationトレイトを実装したコードを使うと、mainメソッドも省略できます。
■ApplicationTraitMain.scala
object ApplicationTraitMain extends Application {
val immutableMapFirst = Map(1 -> "One", 2 -> "Two")
val immutableMapSecond = immutableMapFirst + (3 -> "Three")
Console.println(immutableMapSecond.toString);
def getName(): String = { "name" }
}
処理内容的には前回の記事と同じです。
ですが、mainメソッドではなく、直接クラス定義に処理を記述しています。
Applicationトレイトを継承していると上記のような記述が可能です。
で、実際に実行した結果も下記のようになり、同じです。
■実行結果
Map(1 -> One, 2 -> Two, 3 -> Three)
尚、この記述の実行タイミングはmainメソッドとは違い、『クラスのロードタイミング』になっています。
#下記のキャプチャより

尚、前回のコードを用いて同じ確認を行うとmainメソッドを呼び出して実行しているため、
実行しているタイミングは明示的に違うようです。

実際にApplicationトレイトは何に使えるかというと、
小規模なプログラムを記述するときにmainメソッドを省略できるということと、
後は、『クラスロード時に呼ばれる』内容のため、クラスロード時の初期化を書くのがいいのかもしれません。
Javaでいうstaticブロックのようなノリでしょうか。
実際に、Applicationトレイト継承シングルトンオブジェクトに他のメソッドを定義することも可能でした。
#サンプルコードの「getNameメソッド」
ともあれ、それなりに規模が出てきた時にまた用途を試してみる必要がありそうです。
scalaで出来ることを並べてみる:Map
JavaやC#においてはMapオブジェクトというのは後で何かを追加して使いまわすために
用いられる『ミュータブルオブジェクト』という扱いが基本です。
ですが、scalaのような関数型言語では『イミュータブルオブジェクト』として扱うのが基本だそうな。
実際、Mapにも「scala.collection.mutable.Map」と、「scala.collection.immutable.Map」として
2種類クラスツリーが存在していています。
クラス名称的には微妙にわかりにくい気もしますが。
で、動作も下記のように違ってきています。
■ImmutableMapObjectMain.scala
package jp.gr.kmtn.scalatutorial.grammertips
import scala.collection.immutable.Map
/**
* イミュータブルMapテスト用メインクラス
*
* @author Fukushi-
*/
object ImmutableMapObjectMain {
/**
* イミュータブルMapテスト用プログラムエントリポイント
*/
def main(args: Array[String]): Unit =
{
val immutableMapFirst = Map(1 -> "One", 2 -> "Two")
val immutableMapSecond = immutableMapFirst + (3 -> "Three")
Console.println(immutableMapSecond.toString);
}
}
■MutableMapObjectMain.scala
package jp.gr.kmtn.scalatutorial.grammertips
import scala.collection.mutable.Map
/**
* ミュータブルMapテスト用メインクラス
*
* @author Fukushi-
*/
object MutableMapObjectMain {
/**
* ミュータブルMapテスト用プログラムエントリポイント
*/
def main(args: Array[String]): Unit =
{
val mutableMapFirst = Map[Int, String](1 -> "One", 2 -> "Two")
mutableMapFirst += (3 -> "Three")
Console.println(mutableMapFirst.toString);
}
}
実行結果はどちらも下記のようになります。
■実行結果
Map(3 -> Three, 1 -> One, 2 -> Two)
イミュータブルなMapの場合、+メソッドを使って新しいMapを生成する形で要素を追加。
ミュータブルなMapの場合、+=メソッドを使って新しい要素を追加する形になります。
イミュータブルMapの場合、既存のオブジェクトに影響を与えないことが保障されますが、
要素の追加を行う度に新規Mapが生成されるため、下手すると性能問題になるかもしれません。
ミュータブルMapの場合、既存のオブジェクトに追加されるため性能的には優れそうですが、
いつの間にか状態が変わっている可能性が出てきます。
この辺りを考慮して使い分けるのがよさそうです。
何にしても、使い分けられるのはいいですね。
scalaで出来ることを並べてみる:タプル
JavaやらC#でプログラムを書いていると、『返り値を複数返したい』ケースが出てきます。
特に、違う型の返り値を返したい場合が厄介です。
返り値を返すためだけにBeanクラスを作ったりする。。。というのは面倒ですからね。
・・・まぁ、返り値を複数返したい時点でクラス/メソッド設計が微妙という突っ込みはありますが、
それを言ってしまうと本末転倒なのでここでは省略します。
scalaでは返り値を複数返したい場合、Tupleという型があります。
一言でいえば、異なる型のインスタンスを格納可能なListという感じです。
イミュータブルで、異なる型のインスタンスを混在して格納出来て、型指定も可能。
とりあえず使ってみたサンプルは下記の通りです。
■TupleMain.scala
package jp.gr.kmtn.scalatutorial.grammertips
/**
* タプルテスト用メインクラス
*
* @author Fukushi-
*/
object TupleMain {
/**
* タプルテスト用プログラムエントリポイント
*/
def main(args: Array[String]): Unit =
{
val tuplePair = ("Arg1", 2)
Console.println(tuplePair);
Console.println(tuplePair.getClass());
Console.println(tuplePair._1);
Console.println(tuplePair._2);
val tuplePairGenerics: Tuple2[Int, String] = (100, "Arg2")
Console.println(tuplePairGenerics);
Console.println(tuplePairGenerics.getClass());
Console.println(tuplePairGenerics._1);
Console.println(tuplePairGenerics._2);
val tupleQuintet = ("Args1", 2, 3, "Args4", "Args5");
Console.println(tupleQuintet.getClass());
}
}
で、実行結果は下記の通り。
■実行結果
(Arg1,2)
class scala.Tuple2
Arg1
2
(100,Arg2)
class scala.Tuple2
100
Arg2
class scala.Tuple5
どうやら、指定した引数の数に応じてTuple2、Tuple3...という別々の型が用意されているようです。
いくつまであるかは興味深い所ですが、そんな増える時点で他の所を疑うべきなのは確かですね。
scalaで出来ることを並べてみる:シンボルリテラル
scalaでJavaに無い概念として、「シンボルリテラル」というものがあります。
言ってしまうと指定された文字列を持つラッパーみたいなもので、
同じ引数を指定されたシンボルリテラルはメモリ上で同じ参照を示すことが保障されます。
とまぁ、これだけかいてもわからないので、とりあえずサンプルコードと実行結果を。
■SimbolLiteralMain.scala
package jp.gr.kmtn.scalatutorial.grammertips
/**
* シンボルリテラルテスト用
*/
object SimbolLiteralMain {
/**
* シンボルリテラルテスト用プログラムエントリポイント
*/
def main(args: Array[String]): Unit =
{
val simbolFirst = 'Simbol
Console.println(simbolFirst);
Console.println(simbolFirst.getClass())
val simbolSecond = 'Simbol
Console.println(simbolSecond)
Console.println(simbolSecond.toString())
Console.println(simbolSecond.getClass())
Console.println(simbolSecond.name)
}
}
このコードを実行すると下記の結果になります。
'Simbol
class scala.Symbol
'Simbol
'Simbol
class scala.Symbol
Simbol
実際に同じシンボルリテラルは同じオブジェクトを使用していることが分かります。
(simbolFirstとsimbolSecondは同じオブジェクトID)

注意すべきは、「シンボルリテラル」≠「文字列リテラル」ということです。
シンボルリテラルは文字列とは比較できません。
そもそも型が違うため、マップで比較することも出来ません。
そのため、シンボルリテラル中の文字列リテラルを使用する際にはnameフィールドを参照しましょう。
nameフィールドで文字列と簡単に比較できるため、
プログラム内部での定数取り回しの記述はかなり少なく出来る。。。のかな?
駄目ネタで試すScala 名前付き引数 ~魔法少女まどか☆マギカ編~
前回残っていた、『途中の引数を省略する場合はどうすればいいのか?』について。
デフォルト値によって引数が省略できるにしても、
『どの引数を指定し、どの引数を省略するか?』が指定できないと実際にはまともに使えません。
そんなわけで、scalaでは引数に名前を下記のように指定することが可能です。
メソッド名(引数名1 = 引数1, 引数名2 = 引数2, 引数名3 = 引数3)
実際に使ってみた例が下記。
■NamedArgsMain.scala
package jp.gr.kmtn.scalatutorial.defaultvalue
/**
* 名前付き引数確認用メインクラス
*
* @author Fukushi-
*/
object NamedArgsMain {
/**
* 名前付き引数確認用プログラムエントリポイント
*/
def main(args: Array[String]): Unit =
{
val ancientPuellaA = new PuellaMagi
ancientPuellaA.sealToSoulJem("古代の魔法少女A")
val ancientPuellaAA = new PuellaMagi
ancientPuellaAA.sealToSoulJem(name = "古代の魔法少女AA")
val ancientPuellaB = new PuellaMagi
ancientPuellaB.sealToSoulJem("古代の魔法少女B", "魔法の剣")
val ancientPuellaBB = new PuellaMagi
ancientPuellaBB.sealToSoulJem(name = "古代の魔法少女BB", weapon = "魔法の剣")
val ancientPuellaC = new PuellaMagi
ancientPuellaC.sealToSoulJem(name = "古代の魔法少女C", magica = "この世の呪い")
val madoca = new PuellaMagi
madoca.sealToSoulJem("鹿目 まどか", "薔薇の枝の弓矢", "魔女を全ての時空から生まれる前に消しさる宇宙法則")
val homura = new PuellaMagi
homura.sealToSoulJem(name = "暁美 ほむら", weapon = "時の砂時計の盾", magica = "時間操作")
val sayaka = new PuellaMagi
sayaka.sealToSoulJem(magica = "治癒の魔法", weapon = "サーベル", name = "美樹 さやか")
Console.println(ancientPuellaA)
Console.println(ancientPuellaAA)
Console.println(ancientPuellaB)
Console.println(ancientPuellaBB)
Console.println(ancientPuellaC)
Console.println(madoca)
Console.println(homura)
Console.println(sayaka)
}
}
実際に実行した結果は下記の通り。
魔法少女 名前:古代の魔法少女A 武器:魔法のステッキ 固有魔法:光の魔法
魔法少女 名前:古代の魔法少女AA 武器:魔法のステッキ 固有魔法:光の魔法
魔法少女 名前:古代の魔法少女B 武器:魔法の剣 固有魔法:光の魔法
魔法少女 名前:古代の魔法少女BB 武器:魔法の剣 固有魔法:光の魔法
魔法少女 名前:古代の魔法少女C 武器:魔法のステッキ 固有魔法:この世の呪い
魔法少女 名前:鹿目 まどか 武器:薔薇の枝の弓矢 固有魔法:魔女を全ての時空から生まれる前に消しさる宇宙法則
魔法少女 名前:暁美 ほむら 武器:時の砂時計の盾 固有魔法:時間操作
魔法少女 名前:美樹 さやか 武器:サーベル 固有魔法:治癒の魔法
下記のように引数の名前を指定することで、順不同で引数指定することが可能です。
homura.sealToSoulJem(name = "暁美 ほむら", weapon = "時の砂時計の盾", magica = "時間操作")
sayaka.sealToSoulJem(magica = "治癒の魔法", weapon = "サーベル", name = "美樹 さやか")
とまぁ、ただ当然ながら下記のような制約もあります。
1.名前付き引数と名前なし引数を1回のメソッド呼び出しの中に混在させることは出来ない
2.デフォルト値が定義されていない引数を省略してメソッド呼び出しをすることは出来ない
名前付き引数は多少記述が冗長になるかもしれませんが、
メソッド呼び出し部を見るだけで引数の大体の用途が分かるというのは非常に便利ですね。
駄目ネタで試すScala 引数 ~魔法少女まどか☆マギカ編~
てなわけで(?) ネタ編第2回です。
適切なネタがパッと他に思い浮かばなかったので今回も魔法少女まどか☆マギカ継続で。
今度は何をネタにするかなぁ。。。。
オブジェクト指向言語に限らず、
クラスやメソッドで、
『いくつかの引数は省略しても動くようにしたい』ということはよくあると思います。
その時、Javaだと下記のように同名メソッドをオーバーロードして
同名メソッドをいくつも記述することになります。
■PuellaMagi.scala(変更前)
package jp.gr.kmtn.scalatutorial.defaultvalue
/**
* 「魔法少女」クラス
*
* @author Fukushi-
*/
class PuellaMagi() {
/**
* 名前を示すフィールド
*/
var name_ = "";
/**
* 保持する武器を示すフィールド
*/
var weapon_ = "";
/**
* 固有魔法を示すフィールド
*/
var magica_ = "";
/**
* 契約を行い、魂をソウルジェムに移して肉体をハードウェアに変換する。
*
* @param name 名前
*/
def sealToSoulJem(name: String) =
{
this.name_ = name;
this.weapon_ = "魔法のステッキ";
this.magica_ = "光の魔法";
}
/**
* 契約を行い、魂をソウルジェムに移して肉体をハードウェアに変換する。
*
* @param name 名前
* @param weapon 保持する武器
*/
def sealToSoulJem(name: String, weapon: String) =
{
this.name_ = name;
this.weapon_ = weapon;
this.magica_ = "光の魔法";
}
/**
* 契約を行い、魂をソウルジェムに移して肉体をハードウェアに変換する。
*
* @param name 名前
* @param weapon 保持する武器
* @param magica 固有魔法
*/
def sealToSoulJem(name: String, weapon: String, magica: String) =
{
this.name_ = name;
this.weapon_ = weapon;
this.magica_ = magica;
}
override def toString()=
{
"魔法少女 名前" + this.name_ + " 武器:" + this.weapon_ + " 固有魔法:" + this.magica_
}
でもこれだと正直な話冗長ですよね。
同じメソッドをいくつも書くことになってしまう。
scalaの場合下記のように『引数のデフォルト値』を指定することが可能です。
■PuellaMagi.scala(変更後)
package jp.gr.kmtn.scalatutorial.defaultvalue
/**
* 「魔法少女」クラス
*
* @author Fukushi-
*/
class PuellaMagi() {
/**
* 名前を示すフィールド
*/
var name_ = "";
/**
* 保持する武器を示すフィールド
*/
var weapon_ = "";
/**
* 固有魔法を示すフィールド
*/
var magica_ = "";
/**
* 契約を行い、魂をソウルジェムに移して肉体をハードウェアに変換する。
*
* @param name 名前
* @param weapon 保持する武器 デフォルト値=魔法のステッキ
* @param weapon 固有魔法 デフォルト値=光の魔法
*/
def sealToSoulJem(name: String, weapon: String = "魔法のステッキ", magica: String = "光の魔法") =
{
this.name_ = name;
this.weapon_ = weapon;
this.magica_ = magica;
}
override def toString()=
{
"魔法少女 名前:" + this.name_ + " 武器:" + this.weapon_ + " 固有魔法:" + this.magica_
}
}
こうすると、デフォルトの値が定義されている引数については、
メソッド呼び出し時に値が渡されなくても自動的にデフォルトで指定した値が用いられるわけです。
実際に使ってみた例を書いてみましょう。
■DefaultValueMain.scala
package jp.gr.kmtn.scalatutorial.defaultvalue
/**
* 引数デフォルト値確認用メインクラス
*
* @author Fukushi-
*/
object DefaultValueMain {
/**
* 引数デフォルト値確認用プログラムエントリポイント
*/
def main(args: Array[String]): Unit =
{
val ancientPuellaA = new PuellaMagi
ancientPuellaA.sealToSoulJem("古代の魔法少女A")
val ancientPuellaB = new PuellaMagi
ancientPuellaB.sealToSoulJem("古代の魔法少女B", "魔法の剣")
val madoca = new PuellaMagi
madoca.sealToSoulJem("鹿目 まどか", "薔薇の枝の弓矢", "魔女を全ての時空から生まれる前に消しさる宇宙法則")
Console.println(ancientPuellaA)
Console.println(ancientPuellaB)
Console.println(madoca)
}
}
■実行結果
魔法少女 名前:古代の魔法少女A 武器:魔法のステッキ 固有魔法:光の魔法
魔法少女 名前:古代の魔法少女B 武器:魔法の剣 固有魔法:光の魔法
魔法少女 名前:鹿目 まどか 武器:薔薇の枝の弓矢 固有魔法:魔女を全ての時空から生まれる前に消しさる宇宙法則
こんな感じで、引数を指定しなかった場合、
デフォルトで定義された値が用いられたのがわかると思います。
ただ、これだけだとまだ問題があります。
『途中の引数を省略する場合はどうすればいいのか?』という問題ですね。
とりあえず、それは次回にでも。
駄目ネタで試すScala Actor ~魔法少女まどか☆マギカ編~解説
というわけで、前回投稿中のコードを解説。
■Homo.scala
abstract class Homo(name: String) {
/**
* 名前を文字列型で返す抽象メソッド
*/
def getName(): String
}
オブジェクト指向言語ではおなじみの抽象クラスです。
コンストラクタとして、String型の引数を渡す構成になっています。
尚、コンストラクタの引数にvalを付けると継承メソッド側でエラーとなります。
valはfinalと同様の扱いのため、後から変更することが出来ないためです。
その上で、名前を取得するgetNameメソッドを持ちます。
メソッド本体を定義しなければ自動的に抽象メソッド化されるため、
メソッド側には特にabstractは記述していません。
■Puella.scala
class Puella(name: String) extends Homo(name) {
/**
* 初期化時の名前を取得し、返す。
*/
def getName(): String = { this.name; }
}
人間クラスを継承した少女クラスです。
親クラスのコンストラクタをそのまま使用しています。
尚、getNameメソッドの中ではインスタンスフィールドnameを使用していますが、
これはscalaがコンストラクタの引数に指定した変数名と同名のprivateフィールドを
自動生成して保持するため使用可能になっています。
■Incubator.scala
object Incubator extends Actor {
/**
* メッセージ待ち受けメソッド
*/
def act() {
loop {
receive {
case puellaMagi: PuellaMagi =>
Console.println(puellaMagi.getName() + "、やがて「魔女」になる君たちのことは「魔法少女」と呼ぼう。");
case puella: Puella =>
Console.println(puella.getName() + "、僕と契約して魔法少女になってよ。");
case homo: Homo =>
Console.println(homo.getName() + "、残念ながら君には用は無いなぁ。");
case "exit" =>
Console.println("それじゃあね。"); exit;
exit;
case any: Any =>
Console.println("訳が分からないよ。");
}
}
}
}
objectのインキュベータークラスです。
loopの中のcase分岐を見ればわかるように、
与えられたメッセージクラスに応じて挙動を変えられるようになっています。
マッチングはcase分岐の上から行われ、マッチした処理が実行されます。
Mainメソッド側を見ればわかりますが、
caseにHomoを指定していた場合、子クラス全てがマッチします。
■IncubatorMain.scala
def main(args: Array[String]): Unit = {
// Actor起動
Incubator.start();
Incubator ! new Puella("鹿目 まどか")
Incubator ! new PuellaMagi("美樹 さやか")
Incubator ! new Puer("上条 恭介")
Incubator ! "UnKnown"
Incubator ! "exit"
}
}
Incubatorクラスをstartで起動し、
そこにオブジェクトのメッセージを渡すことで挙動を確認しています。
渡したクラスに応じてActorの挙動が変わっていることが分かりますね。
処理をディスパッチしたり、唯一のデータアクセスオブジェクトを定義したりと、
なかなか面白い使い方が出来そうです。Actor。
駄目ネタで試すScala Actor ~魔法少女まどか☆マギカ編~
前回でIDEの使い方がわかったので、コーディングの効率がかなり増しました。
これで足場は揃ったので、今回からはscalaの要素等を色々試していこうと思います。
で、今回はActorです。
使ったコードは下記の通り。ネタはお察しください(笑
ネタの関係上、Actorに渡すクラス群の名称は全てラテン語になってます。
■Homo.scala
package jp.gr.kmtn.scalatutorial.incubator
/**
* 「人間」クラス
*
* @author Fukushi-
*/
abstract class Homo(name: String) {
/**
* 名前を文字列型で返す抽象メソッド
*/
def getName(): String
}
■Puella.scala
package jp.gr.kmtn.scalatutorial.incubator
/**
* 「少女」クラス
*
* @author Fukushi-
*/
class Puella(name: String) extends Homo(name) {
/**
* 初期化時の名前を取得し、返す。
*/
def getName(): String = { this.name; }
}
■PuellaMagi.scala
package jp.gr.kmtn.scalatutorial.incubator
/**
* 「魔法少女」クラス
* 動作は「少女」クラスに準ずる
*
* @author Fukushi-
*/
class PuellaMagi(name: String) extends Puella(name) {
}
■Puer.scala
package jp.gr.kmtn.scalatutorial.incubator
/**
* 「少年」クラス
*
* @author Fukushi-
*/
class Puer(name: String) extends Homo(name) {
/**
* 初期化時の名前を取得し、返す。
*/
def getName(): String = { this.name; }
}
■Incubator.scala
package jp.gr.kmtn.scalatutorial.incubator
import scala.actors.Actor
/**
* Actor確認用クラス。キュゥべぇ。
*
* @author Fukushi-
*/
object Incubator extends Actor {
/**
* メッセージ待ち受けメソッド
*/
def act() {
loop {
receive {
case puellaMagi: PuellaMagi =>
Console.println(puellaMagi.getName() + "、やがて「魔女」になる君たちのことは「魔法少女」と呼ぼう。");
case puella: Puella =>
Console.println(puella.getName() + "、僕と契約して魔法少女になってよ。");
case homo: Homo =>
Console.println(homo.getName() + "、残念ながら君には用は無いなぁ。");
case "exit" =>
Console.println("それじゃあね。"); exit;
exit;
case any: Any =>
Console.println("訳が分からないよ。");
}
}
}
}
上記がパーツで、実際に実行するプログラムエントリポイントは下記の通り。
■IncubatorMain.scala
package jp.gr.kmtn.scalatutorial.incubator
/**
* Actor確認用Mainクラス
*
* @author Fukushi-
*/
object IncubatorMain {
/**
* Actor確認用プログラムエントリポイント
*/
def main(args: Array[String]): Unit = {
// Actor起動
Incubator.start();
Incubator ! new Puella("鹿目 まどか")
Incubator ! new PuellaMagi("美樹 さやか")
Incubator ! new Puer("上条 恭介")
Incubator ! "UnKnown"
Incubator ! "exit"
}
}
実行すると、下記の結果となります。
鹿目 まどか、僕と契約して魔法少女になってよ。
美樹 さやか、やがて「魔女」になる君たちのことは「魔法少女」と呼ぼう。
上条 恭介、残念ながら君には用は無いなぁ。
訳が分からないよ。
それじゃあね。
とりあえず、解説は次投稿で。
Scala Plugin for EclipseでJavaと同じように出来ること一覧(その1)
とりあえず、導入してみた後、Javaと同じような便利機能がどれだけ出来るかを試してみました。
下記のような開発時に頻度が高くものは一通り出来そう。
出てそれなりに時間がたっているせいか、機能は備わっているようです。
特に、変数名のリネームや呼び出し階層、リファクタ系メニューが普通に使えるのは大きい。
出来ない機能は。。。ま、明らかになり次第ブログに書きます。
■出来る
-コードフォーマット(Shift + Ctrl + F) → フォーマッタはまだ微妙
-変数名/クラス名のリネーム(Shift + Alt + R)
-型階層の表示(F4) → 出来るが、ルートクラスはAnyではなくObjectが表示される。微妙
-呼び出し階層の表示(Ctrl + Alt + H)
-コメントの雛型自動生成(Shift + Alt + J) → /** で書き出すより、こちらの方が優秀
-リファクタ系メニューがそれなりに
-SDKの中のクラスが一部見える(Ctrl + マウスクリック)
-デバッグ実行&ブレークポイントでの停止
Scala Plugin For Eclipse
とりあえずある程度書けるようになったらIDEが欲しくなってしまうのがプログラマのサガですよね。
Javaで現状一番経験があるIDEはEclipseなので、
Eclipseベースのscala開発環境もあるだろう。。。。と見てみたところ、普通にありました。
Scala IDE for Eclipse
Eclipse3.6.2 HeliosのUpdateサイトにscalaのものを設定したら普通にダウンロード&導入完了。

次はscalaプロジェクトの作成ですね。
新しいプロジェクトを作成しようとすると、ScalaProjectが追加されています。


プロジェクトを作成したので、次はソースを作成します。
ClassとObjectがわけて作れる辺りが微妙に便利。


Javaでは当たり前の話ですが、きちんとscalaでも自動補完してくれました。
うーん、やはりこれを知ってしまうとテキストうちのプログラミングには戻れないですねぇ。

とりあえず再度Hello Worldプログラムを記述。
途中でちと気になったのは、「scaladocってどんな感じ?」ということ。
習性のようにコメント入れようとしたら、argsとかのコメントは補完されませんでしたので。
とまぁ、それはそれで。

で、ここまでコードを書いたら後は「Run As」メニューから「Scala Application」を実行するだけですね。

で、実行すると無事コンソールに実行結果が表示されました。
これで基本のきは一本通りましたね~。
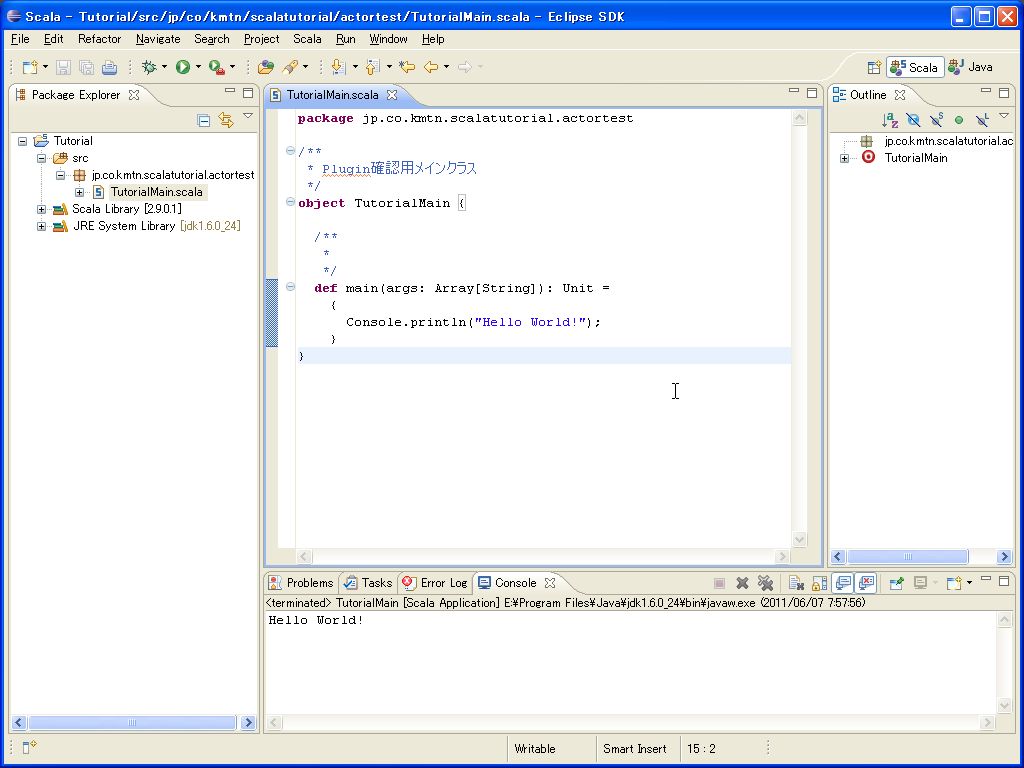
HelloWorld改造版(別クラス参照)でのscalaの特徴とメリットデメリット
とりあえず基本型のコードは書いたのでその中で出てくるscalaの特徴と、
メリットデメリットについてまとめます。
ただ、私がベースがJava/C#プログラマな関係上、
どーしてもその2つの言語との比較になってしまうのでご注意。
1.変数に型宣言が不要
下記のコードを見てわかるように、変数に型宣言必要ありません。
ただ、valという変数を示す宣言があるだけです。
val upper = hellos.map((s:String) => s.toUpperCase())
メリットとしては、型宣言が必要ないため、
1つの関数をより汎用的に様々なクラスで使用できること。
デメリットとしては型宣言が無い関係上その瞬間での型制約が出来ず、
変数からメソッドを呼び出す場合に問題になる可能性が大きい、あたりでしょうか。
メリット:
1つの関数をより汎用的に使用可能。
デメリット:
変数の型に制約が無いため、実行時にエラーとなる可能性があがる。
2.逐次実行時一時的な変数に代入する必要が無い
下記の2行目のように、逐次実行時に一時的な変数に代入する必要がありません。
→ 1行目のように代入(変数:s)して明確にした上で実行することも可能。
_という無名の変数を用いて表現できてしまう。
val upper = hellos.map((s:String) => s.toUpperCase())
upper.foreach(Console.println(_))
これはかなり大きいメリットがあるかと。
なにせ、一時変数がわらわら出来てしまうことがなくなり、可読性がよくなりますので。
但し、デバッグの時に微妙に大変そうだなぁ、とは思います。
リモートデバッグで無名変数ってどーやって指定するんだろ。。。。
メリット:
一時変数を削減し、コードの可読性が向上
デメリット:
デバッグが困難(?)
こんな感じかな。
とりあえず今後もコード書く→特徴まとめるのサイクルをまわしていくか。
HelloWorld改造版(別クラス参照)
今まで生半可理解だったから色々身にしみる。。。というのはさておき。
HelloWorldを改造して、下記のソースを作成しました。
■HelloWhile.scala
class HelloWhile {
def hello(hellos: String*) = {
val upper = hellos.map((s:String) => s.toUpperCase())
Console.println(upper)
upper.foreach(Console.println(_))
}
}
■HelloWorld.scala
object HelloWorld {
def main(args: Array[String]) {
val helloWhile = new HelloWhile
helloWhile.hello("hello", "hellohello", "hellohellohello")
}
}
そんでもって、下記のようにコンパイルして実行します。
C:\work>scalac HelloWhile.scala
C:\work>scalac -cp . HelloWorld.scala
C:\work>scala -cp . HelloWorld
ArrayBuffer(HELLO, HELLOHELLO, HELLOHELLOHELLO)
HELLO
HELLOHELLO
HELLOHELLOHELLO
C:\work>
これでHelloWorldですが、別クラスを参照するHelloWorldの完成。
Javaを知っていると大体分かるんですが、微妙に違う個所も多くあります。
まず、目につくのがクラス宣言の「class HelloWhile」と「object HelloWorld」。
classが通常のクラス定義で、objectがシングルトン定義を表します。
なので、scalaのプログラムを起動する場合はシングルトン定義の中に
mainメソッドを定義して呼び出せばそこから処理がスタートするわけですね。
後は。。。「def hello(hellos: String*) = {...」の個所でしょうか。
さすが関数型言語なだけあって、メソッド自体もイコールでつないで定義しています。
加えて、「Console.println(upper)」→「ArrayBuffer(HELLO, HELLOHELLO, HELLOHELLOHELLO)」
となるように、単にプリントを行った際に型が出力されるのがJavaとは違う所。
他にも何か色々ありますが、ここまで。とりあえずはひたすら書いてみます。。。
HelloWorldプログラムの実行
インストールが終わったので、定番のHelloWorldプログラムを実行してみます。
・・・なんですが、実行手段は下記の通り3通りあったりします。
- 対話方式による実行
- スクリプトによる実行
- コンパイルしての実行
各実行方式の違いについてはまた別記事で。
1.対話方式による実行
scalaコマンドでインタプリタを起動します。
んでもって、下記の通りにコマンドラインに入力し、確認を行います。
背後でどうJavaのオブジェクトにマッピングされているかが出力されるのが面白い所ですね。
C:\>scala
Welcome to Scala version 2.9.0.1 (Java HotSpot(TM) Client VM, Java 1.6.0_14).
Type in expressions to have them evaluated.
Type :help for more information.
scala> val message = "Hello World!"
message: java.lang.String = Hello World!
scala> println(message);
Hello World!
scala>
2.スクリプトによる実行
scalaコマンドにコードが書かれた内容を渡して、実行させます。
一番簡易に実行できる方式ですね。
■HelloWorld-script.scala
val message = "Hello World!"
println(message);
■実行
C:\work>scala HelloWorld-script.scala
Hello World!
3.コンパイルしての実行
予め書いたコードをコンパイルしてclassファイルを生成して、
それを実行させます。
対話方式やスクリプトによる実行とは異なり、クラスとしての構文が必要となります。
■HelloWorld.scala
object HelloWorld {
def main(args: Array[String]) {
println("Hello World!")
}
}
■実行
C:\work>scalac HelloWorld.scala
C:\work>dir
C:\work のディレクトリ
2011/06/02 09:42 <DIR> .
2011/06/02 09:42 <DIR> ..
2011/06/02 09:42 605 HelloWorld$.class
2011/06/02 09:34 47 HelloWorld-script.scala
2011/06/02 09:42 637 HelloWorld.class
2011/06/02 09:41 91 HelloWorld.scala
4 個のファイル 1,380 バイト
2 個のディレクトリ 25,740,607,488 バイトの空き領域
C:\work>scala HelloWorld
Hello World!
C:\work>
Scalaのインストール
復習として、インストールからも一度書いてみます。
Scalaの動作前提は下記です。
- Java1.5以上がインストールされていること
てなわけで、一応Javaがインストールされていることを確認。
OK。
なので、Scalaのインストールに入ります。
ScalaのHPから、Windows用のアーカイブをダウンロードします。
適当な場所に展開して、scala~\binのディレクトリにパスを通します。
んでもってScalaのパス開通確認。

こちらもOK。
画像ばかりで記事が長くなりそうなので一端切ります。
Scalaを導入(?)しました
てなわけで(?)、題名の通り、Scalaを導入しました。
今まで技術要素としてAndroidについて色々投稿していたんですが、
単なるJavaとの違いを出すためにはどうしても
Android固有の技術要素について書かざるをえなかったんですよね。
AndroidでデザインパターンをやってもJavaでしかないわけですし。
ただ、それって検索すれば大抵見つかるもの。
んでもって、どちらかと言うと技術要素の個々を書くよりは
汎用的なプログラミングについて書いてみたかったのもありますので。
というわけで(?)、Scalaの導入から、書き方、環境についても色々書いてみることにしました。
Androidアプリを弄るのは続いているので、時々出てくるかもしれませんが、それはそれで。
デザイン変更
とりあえず、デザインを変更。
Bloggerのテンプレートサイトを漁って集積場というか、埋め立て地っぽいのを持ってきました。
色々カスタマイズ出来ることもよーやっとわかりました。
余計な上部の表示も削除して、表示領域も拡張。
うし、では続いて何か書くか。
まとめ:燃料電池のキホン
先ほど日経Systemsのまとめを投稿したばかりですが、
燃料電池のキホン(ソフトバンククリエイティブ)のまとめも行ったので
投稿しま~す。
以前スマートグリッドについてまとめましたが、
電力のネットワークで熱等もネットワーク化するという内容がありました。
その時は深く考えずにまとめに入れてしまっていたんですが、
燃料電池(発電時に熱が放出される)を組み合わせることを考えると綺麗につながりました。
未来の社会は電力/熱(ガス等も含む)/水素をエネルギー媒体とし、
3要素をネットワークでつないだスマートグリッド社会になる、のかな。
で、エネルギーの生産は地域単位の燃料電池プラント、多様な再生可能エネルギーと共に、
家庭用燃料電池/太陽電池/風力発電機でも行われるようになる、と。
少なくとも、スマートグリッドの本だけではわからなかったことがわかりました。
この辺のエコな未来を目指す本は周辺技術も合わせて読まないと
深い理解には至らない、という証拠ですね。
ともあれ、とりあえず投稿。

燃料電池のキホン(ソフトバンククリエイティブ)のまとめも行ったので
投稿しま~す。
以前スマートグリッドについてまとめましたが、
電力のネットワークで熱等もネットワーク化するという内容がありました。
その時は深く考えずにまとめに入れてしまっていたんですが、
燃料電池(発電時に熱が放出される)を組み合わせることを考えると綺麗につながりました。
未来の社会は電力/熱(ガス等も含む)/水素をエネルギー媒体とし、
3要素をネットワークでつないだスマートグリッド社会になる、のかな。
で、エネルギーの生産は地域単位の燃料電池プラント、多様な再生可能エネルギーと共に、
家庭用燃料電池/太陽電池/風力発電機でも行われるようになる、と。
少なくとも、スマートグリッドの本だけではわからなかったことがわかりました。
この辺のエコな未来を目指す本は周辺技術も合わせて読まないと
深い理解には至らない、という証拠ですね。
ともあれ、とりあえず投稿。

まとめ:日経Systems2011/05
前の投稿から20日くらい空いてしまっておる。
やっべ、こまめに書くようにしないとどんどん日が過ぎていく。
ともあれ、日経Systems2011/05を読んで、
重要だと感じた所をまとめたので投稿しておきます。
・・本当は4月のうちに読み終わっていたんですが、
GWで色々出かけたりしているうちにこの日付に。休日って恐ろしい。
詳細はMindMapにありますが、今回の中で個人的なヒット記事は
後藤田五訓の記事かな、と。
IT関係無いという辺りが微妙ではありますが。
逆に、ビジネスモデリング辺りはいまいち。
あまりそういう経験を積んでこなかった関係上重要に思えないだけなのかもしれませんが。

やっべ、こまめに書くようにしないとどんどん日が過ぎていく。
ともあれ、日経Systems2011/05を読んで、
重要だと感じた所をまとめたので投稿しておきます。
・・本当は4月のうちに読み終わっていたんですが、
GWで色々出かけたりしているうちにこの日付に。休日って恐ろしい。
詳細はMindMapにありますが、今回の中で個人的なヒット記事は
後藤田五訓の記事かな、と。
IT関係無いという辺りが微妙ではありますが。
逆に、ビジネスモデリング辺りはいまいち。
あまりそういう経験を積んでこなかった関係上重要に思えないだけなのかもしれませんが。

プログラマが知るべき5つのこと(?)
もちろん、書籍は「プログラマが知るべき97のこと」です。
ひたすら遅くなりましたが、ようやく読み終わりました。
電車での移動って素晴らしい。
ただ、この本って具体的にどうしろではなく、
行動指針や心構えに対するものがメインであるため、
今後も直接見返す必要がありそうです。
さすがに読んですぐ「コードは未来へのメッセージ」を体現できるとは思いまへんので。
ですが、それだけでは芸がないので、
とりあえず現状の私にとって重要だなぁ、と思うことを5つピックアップしました。
1.名前重要
まつもと ゆきひろ氏の寄稿。
あらゆる機能をデザインする際に名前に最もこだわるとのことですが、非常に同意です。
やっぱり、プログラミングは名前つけに始まり、名前つけに終わると思うんですよね。
基本であり、最も重要な内容だと考えています。
2.DRY原則
スティーブ・スミス氏の寄稿。
「DRY(Don't Repeat Yourself:繰り返しを避けること)原則」ですが、
これも名前と同じくらい重要な事項。
直近ではいいのかもしれませんが、同じコードが一杯あるって
後で酷い目にあうんですよね。
3.単一責任原則
ロバート・C・マーティン氏の寄稿。
「変更する理由が同じものは集める、変更する理由が違うものは分ける」という
単一責任原則(Single Responsibility Principle:SRP)に対する記述。
モジュール分割に対する考えなんですが、
これが見事に出来たなら、再利用性と保守性が高いコードにすることが出来ます。
4.美はシンプルさに宿る
ヨルン・オルムハイム氏の寄稿。
エレガントとか、美とかだけだと個人の感覚に左右されますが、
「シンプルである」は非常にわかりやすい。
コードも機能が絞り込まれたシンプルなものはわかりやすいですね。
5.面倒でも自動化できることは自動化する
ケイ・ホルストマン氏の寄稿。
これも姿勢として重要。
テストコードの実行やビルドやらは毎回手でやるって非効率ですし、
誤りも紛れ込む可能性が大きいんですよね。
かつ、繰り返しになるから間違う可能性も高い。
面倒でも自動化出来るものはしておく、というのは重要ですね。
とりあえず現状はこんな感じ。
今後時がたてば重要だと思うことは変わっていくのかな。
ともあれ、現状は以上。
QConTokyo2011:クラウドパネルディスカッション
ついにラスト。見ていただいた方々、ありがとうございます。
萩原 正義氏&Adrian Cockroft氏&山下 克司氏&玉川 憲氏による、
「クラウドパネルディスカッション」です。
クラウド系セッションの総まとめと、
クラウドを用いて今の日本をよりよくしていこう、というセッション。
東日本大震災を経て、クラウドへの流れが更に強まっています。
ですが、現状はサプライチェーンも、ビジネスプロセスも追い付いていない。
どうすればいいのか、という内容でした。
これも胸が熱くなるセッションだったなぁ。
やっぱり、世の中をよりよいものにしていこう、という意志は欠かせないな。
。。。。そして、全く関係ないですが、
物理サーバに固執するのではなく、
仮想化することでシステムをクラウドに持っていける。。。
というくだりから思ったこと。
物理サーバに魂を縛られたシステム(オールドタイプシステム)と、
新時代を担うシステム(ニュータイプシステム)の対立が生まれるのか!?
ハイ、宇宙世紀ガンダム見過ぎですね。
お後がよろしいようで。

萩原 正義氏&Adrian Cockroft氏&山下 克司氏&玉川 憲氏による、
「クラウドパネルディスカッション」です。
クラウド系セッションの総まとめと、
クラウドを用いて今の日本をよりよくしていこう、というセッション。
東日本大震災を経て、クラウドへの流れが更に強まっています。
ですが、現状はサプライチェーンも、ビジネスプロセスも追い付いていない。
どうすればいいのか、という内容でした。
これも胸が熱くなるセッションだったなぁ。
やっぱり、世の中をよりよいものにしていこう、という意志は欠かせないな。
。。。。そして、全く関係ないですが、
物理サーバに固執するのではなく、
仮想化することでシステムをクラウドに持っていける。。。
というくだりから思ったこと。
物理サーバに魂を縛られたシステム(オールドタイプシステム)と、
新時代を担うシステム(ニュータイプシステム)の対立が生まれるのか!?
ハイ、宇宙世紀ガンダム見過ぎですね。
お後がよろしいようで。

QConTokyo2011:形式手法の現在と実開発への適用可能性
7個目。セッション5回目の時間帯。
小林 健一氏&今井 宜洋氏による、
「形式手法の現在と実開発への適用可能性」。
形式手法って何なのかな?と思っていた所、
「数学に基づいたシステム開発技法」だそうです。
レビューやテストでは全網羅って基本的に出来ません。
ですが、形式手法であれば限定的な条件下においては
完全な網羅照明が可能という辺りは興味深いですよね。
なんか調べたいことがどんどん増えていくなぁ。。。。

小林 健一氏&今井 宜洋氏による、
「形式手法の現在と実開発への適用可能性」。
形式手法って何なのかな?と思っていた所、
「数学に基づいたシステム開発技法」だそうです。
レビューやテストでは全網羅って基本的に出来ません。
ですが、形式手法であれば限定的な条件下においては
完全な網羅照明が可能という辺りは興味深いですよね。
なんか調べたいことがどんどん増えていくなぁ。。。。

QConTokyo2011:Performance Engineering On Twitter
そしてやってまいりました、今回の目玉。
Evan Weaver氏による
「Performance Engineering On Twitter」。
スケールが私の知っているシステムのどれとも桁が違うTwitter。
そのTwitterを成り立たせるための対処についての話。
GCを自分達で作るや、mallocの性質も調査して選択など、
非常にLowレベルから始まった話でした。
ただ、深いトラバーサルを持たないことで性能を見切りやすくするなど、
非常に参考になることも多い内容でした。
にしてもEvan氏、若い。
凄いなぁ。これが世界を変えるエンジニアなのか。

Evan Weaver氏による
「Performance Engineering On Twitter」。
スケールが私の知っているシステムのどれとも桁が違うTwitter。
そのTwitterを成り立たせるための対処についての話。
GCを自分達で作るや、mallocの性質も調査して選択など、
非常にLowレベルから始まった話でした。
ただ、深いトラバーサルを持たないことで性能を見切りやすくするなど、
非常に参考になることも多い内容でした。
にしてもEvan氏、若い。
凄いなぁ。これが世界を変えるエンジニアなのか。

QConTokyo2011:サービスのスケーラビリティと無停止のためのインメモリ技術
セッション5個目。
杉 達也氏の、
「サービスのスケーラビリティと無停止のためのインメモリ技術」。
平たく言うとOracle Coherenceの紹介と、機能の説明。
機能自体はすごくて、資料も非常に充実しているんだけど、
だからこそのっぺりとしたプレゼンテーションがネックだった。
資料を読み上げているだけで終わっているような。。。
発表している最中もスライドの方ばかり見ていて聞いている人の方見ないし。
なので、詳細は資料を見てください、が正直なところかな。
あまり聞いている最中にマインドマップ広がらなかった(汗

杉 達也氏の、
「サービスのスケーラビリティと無停止のためのインメモリ技術」。
平たく言うとOracle Coherenceの紹介と、機能の説明。
機能自体はすごくて、資料も非常に充実しているんだけど、
だからこそのっぺりとしたプレゼンテーションがネックだった。
資料を読み上げているだけで終わっているような。。。
発表している最中もスライドの方ばかり見ていて聞いている人の方見ないし。
なので、詳細は資料を見てください、が正直なところかな。
あまり聞いている最中にマインドマップ広がらなかった(汗

QConTokyo2011:品質検査技術のトレンド
4つ目のセッション。
細川 宣啓氏の
「品質検査技術のトレンド–レビューと測定・欠陥工学を中心に-」。
多分QCon Tokyo2011で私が見たセッションの中で
一番上手かった&見事だったと思う。
地震すらアイスブレークに利用する、テンポもいい、適度に刺激を入れる。
かつ内容としても非常に興味深いものでした。
総合的に見て、細川さん程プレゼンを上手い人はほとんど見たことが無い。
キーノート2の伊藤さんや、最後のクラウドパネルディスカッションは
胸が熱くなる方向性な関係上、軸が違うのであまり比較できませんが。。。。
とりあえず、Hemletの法則は再確認しておこう。

QConTokyo2011:自律的な学びのデザインと誘発
3つ目のセッション。
地味に楽しみだった、井庭 崇さんの
「自律的な学びのデザインと誘発 ― 学びのパターン・ランゲージ」。
これまで「~~を学ぶために何がいいか?」を考えることはあっても、
「学び方のいい形は何か?」を考えることは無かったので、非常に新鮮でした。
なんですけど、「学習パターン ブログ」に非常に詳しくのっているため、
あまりまとめることが無かったなぁ。。。。

地味に楽しみだった、井庭 崇さんの
「自律的な学びのデザインと誘発 ― 学びのパターン・ランゲージ」。
これまで「~~を学ぶために何がいいか?」を考えることはあっても、
「学び方のいい形は何か?」を考えることは無かったので、非常に新鮮でした。
なんですけど、「学習パターン ブログ」に非常に詳しくのっているため、
あまりまとめることが無かったなぁ。。。。

QConTokyo2011:Webアプリケーションエンジニアが見て来た10年
キーノート2つ目のまとめ。
伊藤直也氏の「Webアプリケーションエンジニアがみてきたこの10年」。
この15年を振り返るセッションだったけど、一番聞いてよかったセッションだった。
『自分には”可能性”が無い』、と落ち込み、劣等感に苛まれていたのが情けなくなる。
やっぱりエンジニアである以上、世界をよりよくしたい。
そう原点に立ち戻らせてくれるセッションでした。

伊藤直也氏の「Webアプリケーションエンジニアがみてきたこの10年」。
この15年を振り返るセッションだったけど、一番聞いてよかったセッションだった。
『自分には”可能性”が無い』、と落ち込み、劣等感に苛まれていたのが情けなくなる。
やっぱりエンジニアである以上、世界をよりよくしたい。
そう原点に立ち戻らせてくれるセッションでした。

QConTokyo2011:ドメイン駆動設計
まずは冒頭のキーノートのまとめから。
Eric Evans氏の
「ドメイン駆動設計:複雑な問題群に対する有用なモデル達」。
ぶっちゃけると一番難解だった。
システムレベルのモデリングを行ったことが無いからある意味当然かな.
私は現状ベースのモデルは切られた上で、
その上でミクロな設計をしているにすぎないから。
とまぁ、まとめは下記の通りです。

QConTokyo2011、参加セッション決め台詞(?)一覧
QConTokyo2011 に参加してきました!
まともに参加した初めてのセミナーだったため、非常に新鮮でした。
まとめをしたい所なんですが、時間も時間で眠いため、
参加した各セッション毎の決め台詞というか、ポイント一覧だけまずは投稿します。
ドメイン駆動設計:複雑な問題群に対する有用なモデル達
現実/何にでも使える1つのモデルを追い求めるべきではない。
あくまで"何のために?"をベースに役に立つモデルを選択すべき。
設計時に役に立つモデルが見えていることはまず無い。
Webアプリケーションエンジニアがみてきたこの10年
エンジニアの誇りとは、高度な技術によって得るものではない。
自らが使命とする問題領域をより高度な技術基盤によって発展させることによって
得るものである。
#微妙に違うかもしれません。
自律的な学びのデザインと誘発 ― 学びのパターン・ランゲージ
変化が激しい現代社会では、詰込み型ではなく、
新しい関係性を発見し、自ら意味を編集・構成していけるような「創造的な学び」が必要。
そして、デザインパターンだけでなく、「創造的な学び」にもパターンが存在する。
品質検査技術のトレンド–レビューと測定・欠陥工学を中心に-
品質とは,腕で作り出すものではなく, 科学の力と目で創出するものである
サービスのスケーラビリティと無停止のためのインメモリ技術
サービス無停止と将来の規模拡張に対応可能な仕組み、
“分散キャッシュ” という考え方
Performance Engineering at Twitter
Just do less
Focus on Memory
Access data explicitly and in bulk
let the code make informed decisions
形式手法の現在と実開発への適用可能性
形式手法はレビュー/テストの限界を超えて検証が可能
但し、万能ではない。銀の弾丸は存在しない。
他の手法と組み合わせることで大きな効果を発揮することが出来る。
クラウドパネルディスカッション
クラウドを通して日本をよりよくしたい想いは皆共通。
ただ、『今までと全く同じものを安く手に入れる』ことはクラウドでは出来ない。
それは忘れないでほしい。
福島原発の事故、レベル7てことはチェルノブイリ級?
どうやら、日本政府が福島原発事故のINESレベルを7に引き上げたそうで。
http://www.news24.jp/articles/2011/04/12/10180777.html
チェルノブイリレベルの事象になったということで、
一度チェルノブイリについてまとめて、マインドマップとしてまとめました。
・・・ハイ、嘘です。
状況と発表されている放射性物質の放出量から見てレベル7に達するかも、と見て
予めまとめておいたものです。
なんかいやな予感がしていたんですが、まさか現実となるとはなぁ。
ホントはこんなまとめ出さんで済むように終わってくれればよかったんだけど。。。。
尚、情報のベースは下記のドキュメンタリーより。
-チェルノブイリ原発事故・終わりなき人体汚染 → 1996年(事故10年後)NHKドキュメンタリー
-汚された大地で ~チェルノブイリ 20年後の真実~ → 2006年(事故20年後)NHKスペシャル
てか、チェルノブイリ事故発生時の幼い子供って私と同年代やん。
全く他人事とは思えない。。。。

AndroidでListView中のItemに対するクリックを検知する方法
ListView続き。
いまいち脈絡ないですが、色々ListViewについて調べているうちにわかったということで^^;
ListViewでクリックを検知する方法について説明します。
ListViewでクリックを検知するには、AdapterViewのOnItemClickListenerを使用します。
引数の説明はいまいちわかりにくいですが、下記ソースコードのJavaDocを参照してください。
=====
itemlist.setOnItemClickListener(new OnItemClickListener() {
/**
* ListViewのクリックされたイベントを検知する。
*
* @param targetListView クリックされたItemを保持するListView
* @param clickedView クリックされたView
* @param index ListView中のクリックされたインデックス
* @param rowid クリックされたViewのrowid
*/
public void onItemClick(AdapterView<?> targetListView,
View clickedView, int index, long rowid)
{
//ListViewとして使用するためにキャスト
ListView listView = (ListView) targetListView;
//ListItemとして使用するためにキャスト
ListItem clickedItem = (ListItem) listView.getItemAtPosition(index);
}
});
=====
ちなみに、APIですと引数は下記のように記述されていました。
1.parent The AdapterView where the click happened.
2.view The view within the AdapterView that was clicked (this will be a view provided by the adapter)
3.position The position of the view in the adapter.
4.id The row id of the item that was clicked.
。。。結局実装してみるまでわからなったやん(汗
電力不足が深刻化する東日本で、何が出来るんだろう? → 飽きました。。。
なんというか、つらつらと分析だけやっているの飽きました(爆
元々書きたかったことは電力不足な中、
再生可能エネルギー、燃料電池、スマートグリッドといった
次世代のエネルギー/インフラが台頭してくるのではないか、ということでありまして。
そんなわけで今後はAndroidだけでなく、
そういった次世代エネルギー関連の内容も語られる形になります。
ともあれ、こんな阿呆なブログにつきあって頂いたお礼として、
スマートグリッドの本をちょこちょこ読んで作ったまとめを。
多少バランスが取れていない面はありますが、それは今後ブラッシュアップしていきます。

元々書きたかったことは電力不足な中、
再生可能エネルギー、燃料電池、スマートグリッドといった
次世代のエネルギー/インフラが台頭してくるのではないか、ということでありまして。
そんなわけで今後はAndroidだけでなく、
そういった次世代エネルギー関連の内容も語られる形になります。
ともあれ、こんな阿呆なブログにつきあって頂いたお礼として、
スマートグリッドの本をちょこちょこ読んで作ったまとめを。
多少バランスが取れていない面はありますが、それは今後ブラッシュアップしていきます。

電力不足が深刻化する東日本で、何が出来るんだろう?(その4)
てなわけで、「2.エネルギー戦略を見直す。」について書いていきます。
ようやくですが。
ちなみに電力の不足について書かれた記事はよりわかりやすいとこを見つけました。
#以後、本ブログでも電力の現状を示す際には下記のブログの引用をさせていただきます。
東京電力の計画停電を考える
http://ameblo.jp/kazue-fujiwara/entry-10835236187.html
上記ブログ管理人のkazuさんはサマータイムで節電という1つの結論を出しています。
人/電力消費の『場所的な避難』ではなく、『時間的な避難』という形での対処とするものですね。
とはいえ、一応この一連の記事の目的は「2.エネルギー戦略を見直す。」について
今わかっていることを書いて、まとめておこうという目的のため、
エネルギー戦略に対する感想や考えみたいなものを書いていきます。
まず最初にそもそも発電の手段ってどんなのがあるか、を列挙します。
結果は下記の通り。
1.火力発電:燃料の持つ化学エネルギーを燃焼により熱に変換し、さらに運動エネルギーに変換する発電。
2.原子力発電:核反応により熱エネルギーを得る発電。運動エネルギーへの変換は、通常は蒸気タービンを用いる。
3.水力発電:水の位置エネルギーによる発電。
4.核融合発電:原子核の融合によってエネルギーを得る発電。
5.地熱発電:地熱による発電。
6.太陽熱発電:太陽光の熱エネルギーによる発電。
7.風力発電:風の運動エネルギーによる発電。
8.波力発電:波の運動エネルギーによる発電。
9.潮力発電:潮の干満の位置エネルギーによる発電。
10.炉頂圧発電:高炉の高圧ガスでタービンを回す発電。
11.冷熱発電:LNGの冷熱を利用し、中間熱媒体を液化、循環させて発電。
12.海洋温度差発電:海面の温水と深海の冷水の温度差を利用する発電。
13.人力発電:人間を動力源とする発電。燃料や電池の補給が難しい局面で重宝される。
14.燃料電池発電:燃料の化学エネルギーを直接電力に変換する発電。部分出力でも発電効率が良い。
15.太陽光発電:太陽光エネルギーを太陽電池で直接電力に変換する発電。自然エネルギーなので燃料の購入の必要がない。
16.宇宙太陽光発電:宇宙空間で太陽光発電を行い、それによって得た電力を地上に送る。
17.MHD発電:ファラデーの法則に基づきプラズマなどを用いて発電する。
18.熱電発電:温泉水と河川水などの温度差を利用して熱電変換素子により発電する。
19.振動発電:圧電素子と振動板を組み合わせることにより、音や振動のエネルギーを電気エネルギーに変換する発電。
・・・・なんか、思ったより一杯あるんですね。
まずは分類分けしよう。ただ時間も時間のため、分類分け等は次回以降に。
電力不足が深刻化する東日本で、何が出来るんだろう?(その3)
てなわけでその3。
全く解決策ではなく、『真夏の停電をいかに乗り切るか』についてまずまとめちゃいます。
備忘録としても。
まず、真夏の停電において障害となるのは下記の3つです。
1.照明が無い暗闇
2.猛暑による体力の消耗
3.猛暑による食べ物の急激な痛み
1.照明が無い暗闇
夜は真夏であろうと暗いです。
長期にわたって夜間の停電が続くことを考えると、下記の2条件を満たした照明器具が必要でしょう。
A.LEDを使用している
→ LEDの長寿命は大きいです。使い続けるため、電灯みたいに途中で切れては困る。
B.充電式か、今持っている充電池で使用することが出来る
→ 重要。
おそらく、夏季にも照明器具向けの乾電池は不足するはず。
不足している状況下で数日でワンセットの乾電池を消耗することは出来ない。
なので、Eneloop等の繰り返し使用できる充電池と、
そのサイズの充電池で使用可能な照明器具を入手する必要があります。
A、Bを満たす照明だと、充電池が入手しやすい単3電池、単4電池で稼働する
LEDランタンが理想かな?
ただ、今は入手できないので、4月か5月を待ちますか。。。
2.猛暑による体力の消耗
真夏に冷房を使用せずに凌ぐとひたすら体力を消耗します。
なので、少しでも消耗を抑えるためには。。。
何がいいんだろ。
扇風機と、保冷剤を多めに用意しておくくらい、しかないのかな。
後は、水分を頻繁に摂取できるよう確保しておくくらいでしょうか。
3.猛暑による食べ物の急激な痛み
停電の間冷蔵庫も止まります。
ただ、今と違うのは猛暑であるため、3時間であっても冷蔵庫の停止が響きます。
であれば。。。こちらも大きめの保冷剤を用意するか、
ジップロックに水をためて凍らせたものを保冷剤代わりに使用するといった対処が必要となります。
まとめ
夏までに下記のグッズを買い込んでおこう。
今は混乱期だから、物流も一通り回復した4月下旬あたりに。
1.LEDランタン(単3電池、単4電池で使用可能なもの)
2.EneloopかEvolta充電型の充電可能な電池
3.扇風機
4.保冷剤
5.ジップロック
電力不足が深刻化する東日本で、何が出来るんだろう?(その2)
てなわけで続きです。
電力不足が深刻になっていて、
それが急場の発電所の建設だけではどうやら解決しないだろう。
ただ、原子力発電の今後は絶望的だろう、というのが前回までの内容。
今回の地震は間違いなく戦後最大のインパクトを日本に与えた災害でしょう。
被害の大きさだけでなく、日本の社会への影響も。
多分、今のままでは東日本のエネルギー不足は解消しません。
ということは、おそらく取るべき策は下記の2つのうちいずれかではないかなぁ、
と考えています。
1.東電地域にある都市/設備/人口を日本各地に分散させる。
2.エネルギー戦略を見直す。
1.東電地域にある都市/設備/人口を日本各地に分散させる。
電力を使用する存在自体を地方に移動させてしまおう、という解決方法。
ただ、これについては個々の組織が自発的にやるとは思えないため、
多分ごく一部しか実現しないはず。
#取引先が関東にあるままだと移動できませんしね。
2.エネルギー戦略を見直す。
根本解決につながる可能性ですが、5年10年単位の時間がかかります。
1は多分実現しない、2は5年10年かかる。。。
あれ?てことは5年間くらいの夏は今行われている計画停電をはるかに
上回る規模の計画停電が実施され続ける、ということですよね。
本当は2について書きたかったんですが、
まずは真夏の停電を乗り切るために必要なものを列挙しておく必要がありそうです。
ではまずそれをその3に。
電力不足が深刻化する東日本で、何が出来るんだろう?(その1)
てなわけで、思ったことのまとめ開始。
まず前提として、東京電力の発表によると、現状で東電区域において電力が不足しています。
A.3月中旬の総発電能力:3350万KW
B.3月中旬の総必要電力:4700万KW(節電+計画停電でAにあわせている)
Aについては4月前半までに
検査中だったり、フル稼働していない火力発電所をフル稼働状態に
持っていくことで4000万KWまで供給能力を持っていく予定のようです。
4月になれば暖房はほぼ使用されなくなる関係上、4000万KWあれば
必要な量はほぼ確保できる模様。
なので、4末時点では下記のように重要と供給はつりあいます。
C.4月末時点の総発電能力:4000万KW
D.4月末時点の総必要電力:4000万KW
ですが、このページや、このページを見ていると、
夏季に必要となる電力量は6000万KW~6400万KW程にもなる模様。
#暖房と違って、冷房は電力で行う他ないから、という話なのでしょうか。
東電側も数か月で動作開始可能なガスタービン発電所(出力30万KW級)をいくつか
建設する予定のようですが、それでも4800万KW程までしか行かないようです。
ということは、下記のように最大1600万KWのギャップが出る。
夏の猛暑の中、計画停電突入、ということになってしまうわけです。
E.夏季の総発電能力:4800万KW
F.夏季の総必要電力:6000~6400万KW
かつ、今回の福島原発の事故によって、
今後原子力発電所を新設/修理することは極めて困難な状況になっていると思います。
世論/国際情勢的に。
もしかすると今停止している原発を再開することすら無理かもしれない。
てことは、おそらく上記の1600万KWを
今までとは違う手段を持って埋める必要がありそうです。
そのために何が出来るか、を考えた結果を書いていこうと思います。
東北関東大震災から1週間あけて
東北関東大震災により被害を受けられた皆さんに心よりお見舞い申しあげます。
東北関東大震災では私自身も直接被災地区ではないにしろ、
停電やモノ不足による影響をかなり受けました。
幸い、動くのが早かった&そもそも1人暮らしであまりモノを必要としない関係上、
生活必需品については困ることはありませんでした。
ただ、おかずのバリエーションは減ってたかな。そのくらいでした。
なんですが、電力不足によって街から明かりが消え、
物流が麻痺している都市を見ていると物思う所がありました。
とまぁ、ただそれはまた違う話題になるので、次の投稿で。
後、いまいち今までのデザインは見にくかったので変更しました。
すっきりして見やすくなったかと思います。
Androidアプリでリストを最後まで読んだら検知する方法(その2)
Androidアプリでリストを最後まで読んだら検知する方法
の続きです。
とりあえず、『リストを最後まで読んだら検知すること』は成功しました。
ともあれ、これだけでは全くわからないので、
使ったメソッドと、その動作についてまとめます。
『リストがスクロールしたこと』を検知することは前の投稿にも書いたとおり、http://developer.android.com/reference/android/widget/AbsListView.OnScrollListener.html
を使います。
使用するメソッドはonScrollです。
ただ、APIとして記述されている内容だけだとぶっちゃけわかりません(汗
英語力不足なんでしょうか。。。。
仕方がないので動作確認した結果、下記の動作となることがわかりました。
firstVisibleItem:一番上に表示されてるアイテムのインデックス
visibleItemCount:画面に表示されてるアイテム数
totalItemCount:リストに存在している全アイテム数
図に示すと下記のようになります。

なので、「firstVisibleItem + visibleItemCount == totalItemCount」の条件を
満たした場合のみOnScrollからイベントを発生させるようにすれば、
リストを最後までスクロールした場合に処理を行うことが可能となります。
差分がtotalの10%になったら発動、というようにすれば
「下の残りが少なくなったら随時追加読み込みを行う」という処理も
可能になります。
さて、とりあえず検知と、イベント発動が可能であることがわかったので、
後は読み込み処理を上手く共通化して扱うための手法、ですね。
作成が成功したらその3として投稿します。
AndroidのHttpURLConnectionで、httpsかつBasic認証込みの通信がこける。。。
もう1つ。
Androidアプリ内部で、HttpURLConnectionを用いてhttpsのBasic認証を行った場合
なぜか「1回目の通信のみがこける」という事象が発生中。
原因は不明ですが、1回目の通信はhttpsstatuscodeが-1なので、
そもそも外部にアクセスに行けずにこけている模様。
で、代わりになるようなものが無いか調べていたのですが、
DefaultHttpClientだと何とかなる可能性があります。
「https通信」「Basic認証」は各々実現している情報(下記2ページ)がありました。
・Android で HTTPS 通信をする
http://www.pshared.net/diary/20091123.html
・DefaultHttpClientでBasic認証使ったアクセスを行う
http://techbooster.jpn.org/application/3391/#more-3391
なので、「https通信」「Basic認証」の両立も可能?と考えたい所ではありますが、、、
とりあえず、試すまでにはちと間が空きそうです。
Androidでプロキシ使うとhttps通信が動かない!
最近Androidエミュレータを用いてAndroidの通信内容を確認するために
ローカルプロキシを適用していたんですが、
よく通信に失敗するという状態になっていました。
で、確認してみたんですが、https通信の時だけこけている模様。
http通信は正常に中身が確認できていたので、
https通信だけピンポイントにこけているようでした。
で、なぜかな~と調べてみると、Androidのバグ情報が。
http://code.google.com/p/android/issues/detail?id=2690
どうやら、Androidのバグとして、プロキシを通したhttps通信は出来なかったようです。
尚、このバグはGingerbread、つまりAndroid2.3では解消している模様。
なので、Androidエミュレータのhttps通信の中身を確認したい場合、
Android2.3のエミュレータを使う必要がありそうです。
Androidアプリでリストを最後まで読んだら検知する方法
現在作成中のアプリで、
「リスト表示されたアイテム(ListView)を最後までスクロールしたら次を読み込む」
処理が必要になったのですが、
Web上を調べてみてもいまいち見つからなかったので
メモとしてここに残しておきます。
とりあえず、検知出来そうな手段は見つけました。
http://developer.android.com/reference/android/widget/AbsListView.OnScrollListener.html
が使えそうです。
このページにある下記のメソッドは、
スクロールした際にコールバックを返す、というメソッドのため、
最後までスクロールしたら次読み込む用にすれば実現できそうです。
とまぁ、とりあえずはテスト用のプログラムを組んで確認してみよう。。。
public abstract void onScroll
(AbsListView view, int firstVisibleItem, int visibleItemCount, int totalItemCount)
Androidエミュレータのネットワーク構成
前回の投稿で気になったので調べてみました。
Androidエミュレータは基本的にDalvik仮想マシンを起動し、
その上で動作しています。
そのため、起動時に仮想ネットワークを構成してその中にエミュレータがいるかたちになります。
仮想ネットワークの構成に関しては下記を参照。
https://sites.google.com/a/techdoctranslator.com/jp/android/developing/tools/emulator#emulatornetworking
Dalvik仮想マシン1つ1つに仮想ネットワークを構築するようなので、
Androidエミュレータ同士を通信させるには工夫が必要なようです。
https://sites.google.com/a/techdoctranslator.com/jp/android/developing/tools/emulator#connecting
こんどやってみるか。
Androidエミュレータがネットワークにつながらなくなったら
一番簡単かつ確実な手段=再起動
。。。と書いちゃうと全てぶち壊しではありますがw
ただ、基本Androidエミュレータは再起動を繰り返すものでしょうし、
再起動できるならしてしまった方がいいです。
ただ、それが出来ない場合は、ということで。
原因は大抵DNSによる問題解決が出来ないことです。
なので、下記のページ等を参考にDNSを再設定すべし。
■Androidのエミュレータがネットワークに接続できない場合の対処方法
http://magpad.jugem.jp/?eid=199
Xperiaで通話着信音、メール着信音を設定する方法
Xperiaを購入してから10カ月以上たちましたが、
今回初めて通話着信音、メール着信音をプリセットじゃない音に設定しました。
すると、意外にこの辺厄介なことが判明。
とりあえず、設定方法を。
ちなみに、「メール着信音」と同じ操作を行えば
通話着信音を設定することも可能です。
前提として、音楽ファイルをAndroid端末にダウンロードしておきます。
後、アストロファイルマネージャーもインストールしておくと何かと楽。
■通話着信音設定方法
1.ファイルマネージャーから音楽ファイルを選択して、
Mediascapeを使用して起動&再生する。
2.再生中にメニューボタンを押下して、「着信音に設定」を選択
3.通話着信音設定の選択肢にMediascapeで設定したファイルが
加わっているので、そこから設定
この操作をやってみたところ、メール着信音側には選択肢が追加されず。
てなわけで、下記の操作が必要になりました。
■メール着信音設定方法
A.通話着信音設定方法の「1」「2」を実行しておきます。
B.Androidマーケットから「Tone Picker」をダウンロードしてインストール
C.GmailアプリやGmailの通知系アプリのメール着信設定画面に
「Tone Picker」が追加されているので選択。
D.再度「Tone Picker」を選択する。
するとMediascapeの再生履歴が表示されるので、そこから選択。
以上の操作で設定できます。
後、何故か「D」のタイミングでアストロファイルマネージャーを選択して
音楽ファイルを指定した場合何故か再生されず。
音楽系アプリの履歴データから選択する必要があるようです。
意外に厄介な設定でした。
Eclipse+Android SDKでビルド中にこける
なんか、この間Eclipse+Android SDKでビルド中に落ちる事象が発生。
エラーを見てみると、
java.lang.IllegalArgumentException: already added: LXXXXX
てな感じでビルド途中にで例外を吐いて、最終的に
Conversion to Dalvik format failed with error 1で落ちるという状態。
エラーメッセージから丸わかりですが、
どうやらAndroidSDKでは「同じクラス」を2度ロード(?)することは出来ないようです。
見た感じ、クラス名をキーとしてバイナリファイルをマッピングし、
それをロードして使用している?
だからキーが重複したときに落ちるとか。
解消方法は、LXXXXと表示されているクラスが2度ロードされないように
クラスパスを見直すこと。
そんな構成にはなっていない、ということであれば、
クリーンビルドをすれば解消するはずです。
Androidで出来ることをどう実現するか知るためには?>ソースが公開されているアプリのソースを読みましょう
別にこれはAndroidに限ったことではないんですが、
アプリをどうやって作ればいいのか知るための一番の近道は、
『ソースが公開されているアプリのソースを読むこと』です。間違いなく。
あ、ただその前にAndroidの入門書1冊くらいは読んでおく必要があるか。
てなわけで現状一押しのソースを。
http://www.netmite.com/android/mydroid/packages/apps/AlarmClock/
Android公式のアラーム付時計のソースです。
アラーム付き時計って簡単に見えていろんな要素を含んでいて、
プラットフォームに依存した処理も多いため、
一通り作れるようになれば基礎的な機能はそれなりに押さえられるかと。
・レイアウト配置
・一定時間ごとの描画(表示している間だけ)
・サービス化
・メディア再生
後は、通信/認証系のアプリと、位置情報を利用したアプリが作れれば
基礎はほぼ舐めたと言っていいのかな。
今度その辺りも探してみよう。
統計情報を見ていて思ったこと。
統計情報を見ていて思ったことなんですけど、Androidについて
検索した結果から来ている方が多い。
やっぱりヘボかろうがなんだろうが
Androidについていじった結果を書いていくのが一番いいのかな。
仕事のプロ 仕事のアマ:まとめ
「 仕事のプロ 仕事のアマ」(長谷川 和廣)を読み終わりましたので
マインドマップをアップします。
ある意味当たり前のことなんですけど、
実際にやってみると中々実践できないという内容/心得が
仕事のプロが持つべき心得として記述されています。

マインドマップをアップします。
ある意味当たり前のことなんですけど、
実際にやってみると中々実践できないという内容/心得が
仕事のプロが持つべき心得として記述されています。

仕事のプロ 仕事のアマ:その1
本屋でちと立ち読みして買った本ですが、
「 仕事のプロ 仕事のアマ」(長谷川 和廣)が面白い。
今読んでいる最中ですが、いくつか書いてみます。
ハッとさせられることが非常に多い。
○1 勝ちぬく人から法則を学びなさい
仕事のアマ 返答は正確にする
仕事のプロ 返答はいち早くする
出来る社員は現時点で裁量の範囲で答えられることをまず回答する。
単に「持ちかえらせてください」とだけは言わない。
仕事のアマ 本物を真似たら、それはニセモノ
仕事のプロ 本物から学び、より優れた本物を作りだす
既に世に送り出されている「本物」には本物のエッセンスが含まれているため、
エッセンスを基により優れた本物を作りだせるということ。
仕事のアマ 知識はあらかじめ学んでおく
仕事のプロ 仕事の現場で「体験」から多くを学ぶ
必要になったことが一番効率よく学べる、ということ。
将来必要になるかもしれない、レベルの事を学んでも効率は悪い。
仕事のアマ 時には、リスクをおかす勇気も必要だ
仕事のプロ 全てをやりつくせば、リスクをおかすことは怖くない
準備を全て行えば、リスクを取る事は怖くない。
必ず、何かの結果が出るはずだ、ということ。
ここまで言い切れるだけの準備を行えるなら、確かに怖くない。

分散システム/クラウド系の技術諸々
Androidだったり、クラウドだったり、分散システムだったりするののメモ
Androidをデバッグし、メモリダンプからデータを復旧する
http://monoist.atmarkit.co.jp/fembedded/articles/filesys/10/filesys_10a.html
Androidを組み込みボードにインストールして、
Linuxのメモリ管理を見よう、という企画。
自分で何かハードを組むことは無いでしょうけど、こういうのは面白いなぁ。
Java ベースのNo SQL ミドル Apache Cassandra
http://gihyo.jp/dev/serial/01/cassandra/0001
分散DB/FSがフルにJavaで構築されているのって珍しいなぁ。
Hadoop MapReduceプログラムを解剖する
http://codezine.jp/article/detail/5582
今更といえば今更ですが、Hadoopも。
このへんの概念一度きちんと学んでおく必要がありそう。
Thrift
http://blog.broomie.net/index.cgi?id=38
これも今更といえば今更ですが。
後は、Thrift、ProtocolBuffer、MessagePackって、性能に関しては下記ページみたいに
調査結果があるんだけど、開発コストとしてはどんなものなのかな?
パッと見た感じ、通信スケルトンまで自動生成してくれるThriftがいいように見えるんだけど。。。
http://d.hatena.ne.jp/shot6/20091112/1258002372

{kind=link}
{kind=link}
アンカー:IDEの最近
分散バージョン管理システム「Mercurial」
http://journal.mycom.co.jp/column/ide/093/index.html
GitでなくてMercurialかぁ。
Google Codeでも使われているし、情報はおっておくべきかな。
Htmlコーディング支援「Zen Coding」
http://journal.mycom.co.jp/column/ide/098/index.html
モック書く時には使えるのかなぁ。
アンカー:その他OSSJavaもろもろ
昨日に引き続き業務ソフトのJava OSSを調べていましたが、
http://java-source.net/
にその辺りの一覧っぽいのがある模様。
但し、英語ベースのもののみのようですが。
あとは、「OSS Javaフレームワークはどんどん高度化している」にあるように、
単なるアプリ開発のフレームワークから、
業務レベルに特化したパッケージがどんどん登場している模様。
こんな風に。
・エンタープライズサービスバス(ESB Mule、Servicemix、Spring Integration、JBoss ESB)
・エンタープライズポータル(Liferay、JBoss Portal)
・ビジネスインテリジェンス、帳票(Pentaho、Jasper Report)
・ビジネスプロセス管理(jBPM)
・ビジネスルールエンジン(Drools)
・文書管理(Alfresco)
なんつーか、こういった業務に関連づいたものを作るときは
まずOSSで何があるかを探しまわれってことなんでしょうねぇ。
アンカー:Adempiere/Compiere:OSSのERP/CRM
気になったので残しておこう。
これまでERP/CRMとかのソフトウェアって、
商用なソフトウェアばかりかと思っていたんですが、
下記みたいにOSSのソフトウェアも存在するらしいです。これ結構意外。
Adempiere
Compiere
もしかすると、こういったOSSをベースに
後、AdempiereについてはリポジトリでJavaで書かれていることを確認。
これは普通に改造していろんなものに使えるんじゃないかな?
CompiereはCVSリポジトリは見つかったんだけど、
ソースはまだ見えない。。。とりあえず何の言語で書かれているか
どうか、くらいは確認しておこうっと。
追記:
CompiereはJavaベースのようなのですが、
なんか既にリポジトリはほぼ稼働していない状態?
ファイルが見つかりませんでした。
ただ、ソースコード一覧はダウンロードできて、きちんとJavaでした。
登録:
投稿 (Atom)